

Anthropic has launched the latest version of its Sonnet model, Claude Sonnet 5, which is comparable to Opus 4.8 on benchmarks. However, a wall of benchmarks, a couple of cost-performance curves, and a line about how this one is more capable don't tell the whole story. Not to discredit any benchmarks, but they are less useful if you just want to know whether it's worth switching your daily driver.
So instead of reading the charts, I did what I always do. I tested Claude Sonnet 5 with five tasks that mirror the actual work I would throw at an AI model in a normal week.
- A vibe-coded browser game
- A messy spreadsheet I fixed inside Cowork
- A 12-page contract,
- An agentic research job, and
- One deliberately under-specified planning problem to see how it can handle ambiguity.
What Anthropic actually says about Sonnet 5
Anthropic is pitching Sonnet 5 (released June 30, 2026) as the most agentic Sonnet model yet. That means it is an AI model that can plan, use tools like browsers and terminals, and run autonomously at a level that used to require bigger, pricier models. The headline claim is that its performance sits close to Opus 4.8 but at a lower price, and that it's a clear step up over Sonnet 4.6 on reasoning, tool use, coding, and knowledge work.
A few specifics worth knowing before you test:
- Effort levels: Like recent Claude models, Sonnet 5 lets you dial how hard it thinks. Anthropic's own curves (on the BrowseComp agentic-search and OSWorld-Verified computer-use evals) show it's most cost-efficient at medium effort and that, at extra-high effort, it can match Opus 4.8 on some tasks.
- Price: The introductory price is $2 for every million input tokens and $10 for every million output tokens until August 31, 2026. After that, the prices will increase to $3 for input tokens and $15 for output tokens. For comparison, Opus 4.8 charges $5 for input tokens and $25 for output tokens. The API model string is claude-sonnet-5.
- Where you get it: It's now the default model on the Free and Pro plans and is available on Max, Team, and Enterprise, plus Claude Code, Cowork, and the Claude Platform.
- Safety: Anthropic has reported lower rates of hallucination and sycophancy than Sonnet 4.6, better resistance to prompt-injection, and deliberately weak cybersecurity skills, with cyber safeguards on by default.
One important detail in the launch is mentioned in a footnote: Sonnet 5 uses a new tokenizer, which means the same text can be converted into about 1.0–1.35 times more tokens than before. The introductory pricing is trying to keep costs similar, but you should keep an eye on your bills.
With that out of the way, here's how it actually felt to use:
1. Vibe-coding challenge: a single-file browser game
Prompt:
Build a complete, playable browser game in one HTML file called "Lantern Tide."
I steer a paper lantern left and right along a dark river using the arrow keys, collecting fireflies that drift upward while dodging falling raindrops that snuff the lantern.
Each firefly adds to a glow meter that visibly brightens the whole scene; three hits from raindrops end the run.
Add a rising difficulty curve, gentle particle trails behind the lantern, a soft screen-glow that pulses with the combo, a parallax starfield, and ambient audio built only with the Web Audio API.
Vanilla JS, no libraries, no external files.Verdict: I used Sonnet 5 high, and it worked for about 8 minutes and 50 seconds. In my opinion, the output was polished and impressive, matching the quality of Opus 4.8. The game ran well on the first try; the arrow controls were responsive, the glow meter brightened the background, and the parallax starfield added depth.
2. Reading a real contract (PDF knowledge work)
Prompt:
Attached is a multi-page services agreement.
Pull out every obligation that falls specifically on the Vendor (not the Client), list the deadline attached to each, and flag any clause vague enough to cause a dispute.
Then draft a one-page plain-English summary I could hand to a non-lawyer.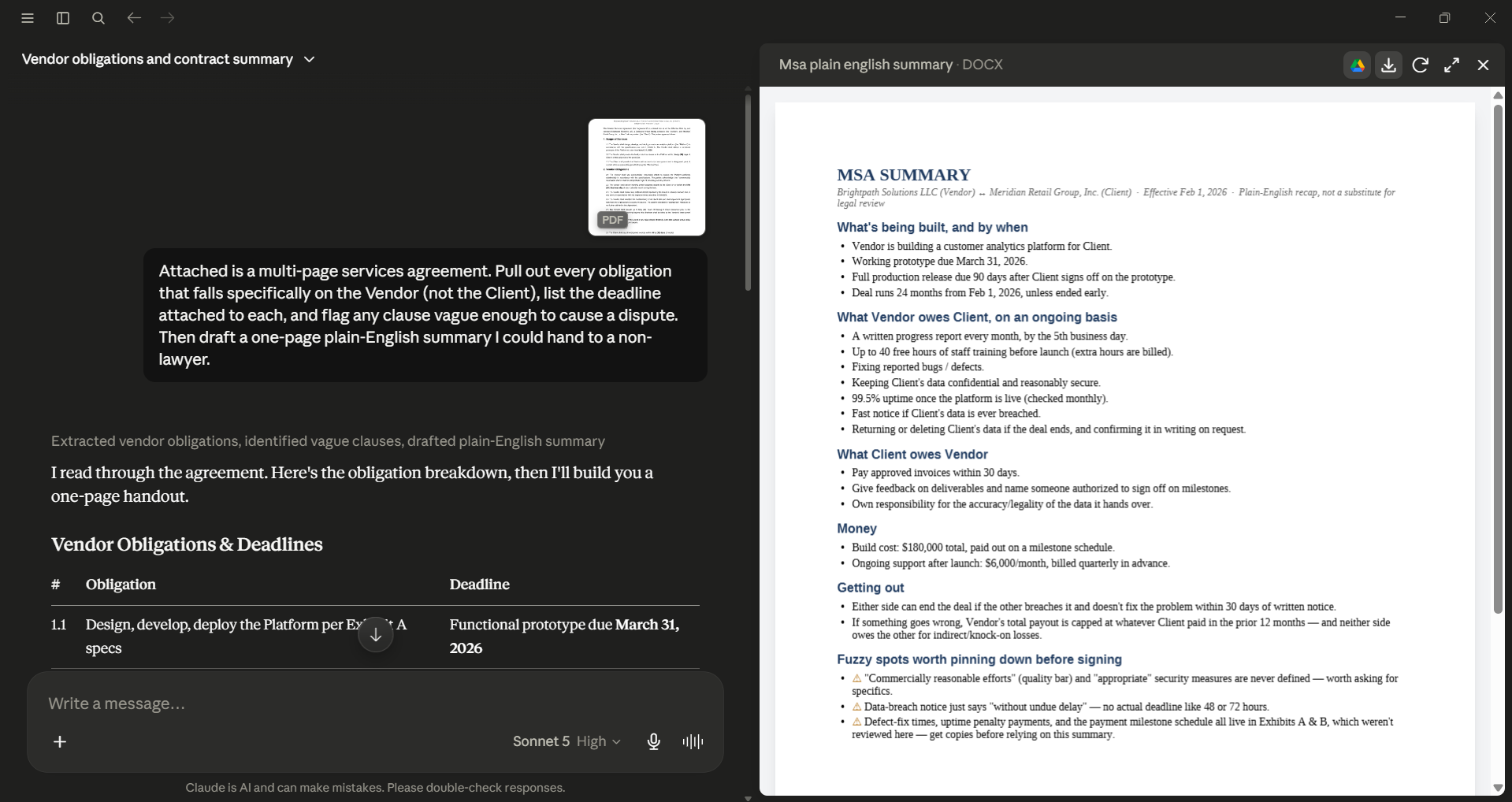
Verdict: It provided a clear list of vendor obligations with deadlines, avoiding made-up deadlines, which is a common mistake. It flagged risky clauses, like those using vague terms such as "commercially reasonable efforts" and an SLA that refers to an exhibit without explaining the remedy. It explained the risks of each clause instead of just pointing them out. The plain-English summary was the best part. It was accurate and concise (which I care about), making it easy for non-lawyers to understand.
AdCreative.ai: An AI-powered platform that automates the creation of high-performing ad creatives for social media and display campaigns
3. The Cowork test: fixing a messy spreadsheet end-to-end
I wanted to see how Sonnet 5 could handle this task, because of its agentic capabilities. I added a deliberately poorly made sales export in a Cowork folder and allowed Sonnet 5 to work on it.
Prompt (in Cowork):
There's a file called messy_sales_2025.xlsx in this folder.
It's a mess: inconsistent date formats, region names spelled three different ways, blank rows, revenue stored as text with currency symbols, and a couple of obvious duplicate orders.
Clean it, then build me a second sheet with total revenue by region and by month, add a bar chart of monthly revenue, and write a 150-word summary of what the data actually says.
Save it as a new file so my original is untouched.Verdict: This played to Sonnet 5's strengths. It used 8 tools, ran 6 commands, and applied a skill. It handled a messy data sheet, fixed errors, and organized everything into a clean sheet. Then, it created a summary sheet, added a chart, and saved a new workbook without changing my original file, just as I requested.
What impressed me was its ability to check its own work. It identified two rows with blank regions without being prompted. I would still review the output before sharing it, but Sonnet 5 probably saved me about half an hour. Sonnet 5 in Cowork is a great choice for automating the tedious parts of data cleanup.
4. Agentic research + synthesis
Prompt:
Research the 5 most talked-about AI coding agents right now.
For each, note the pricing tier, the one feature people actually praise, and the most common complaint.
Put it in a comparison table, then write a 250-word take on where the category is heading, and be explicit about which of your facts might be stale.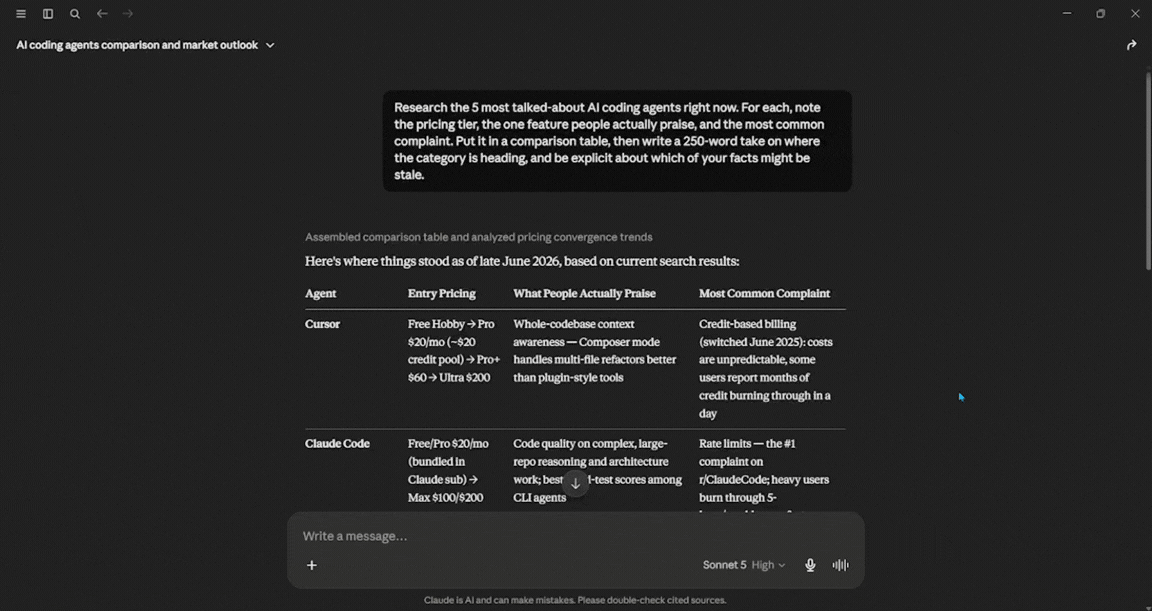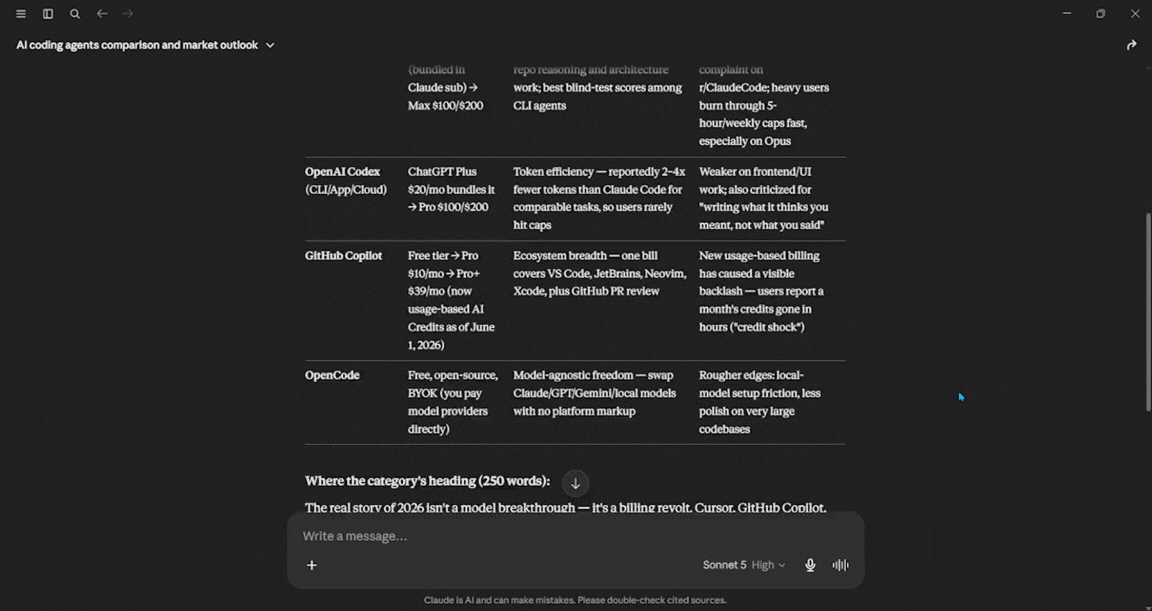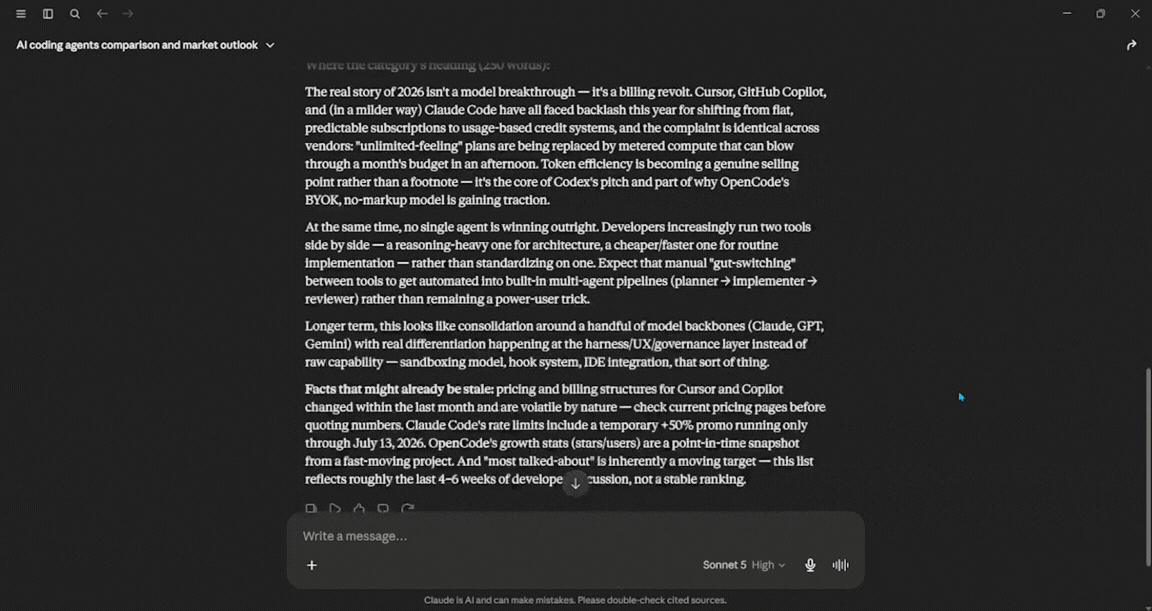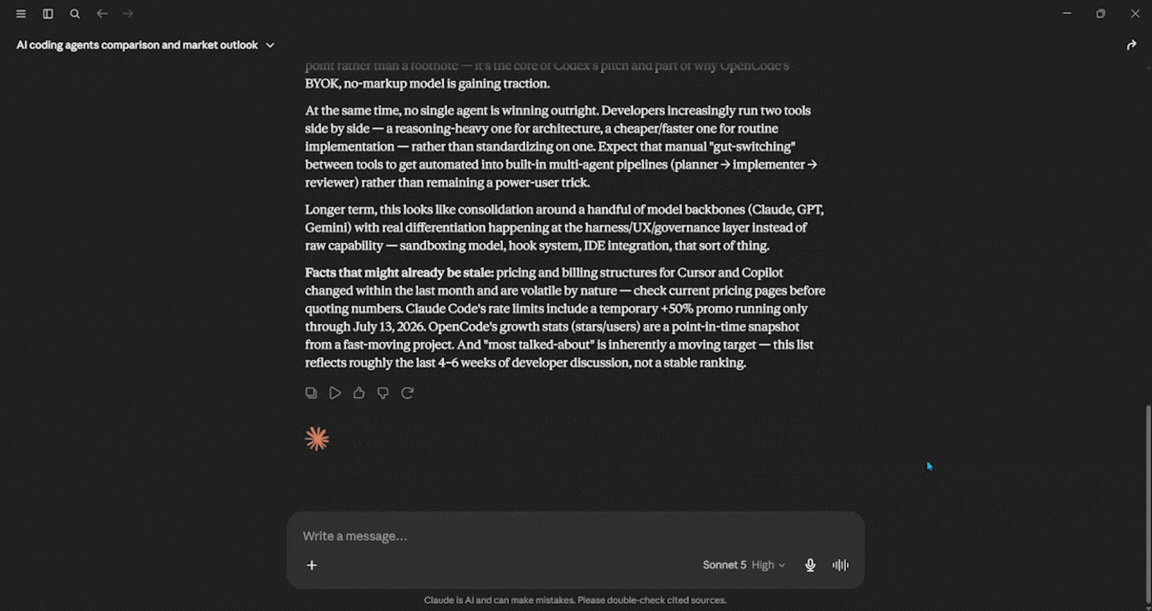
Verdict: This test shows the difference between a chatbot and an agent. Sonnet 5 acted more like an agent. It ran several searches and created a clear comparison table. I noticed that it marked two pricing figures as possibly outdated. This kind of self-awareness is what Anthropic aims to achieve with this version. If you need a reliable briefing based on solid information that stays within the facts, this is a good choice.
5. Reasoning under ambiguity
Prompt:
I want to quit my job in 4 months to freelance, but I have 3 months of savings and no clients yet.
Don't cheerlead me.
Audit whether this is actually realistic, build a month-by-month plan that de-risks it, and tell me plainly what I should NOT do.Verdict: This was one of my favorite responses out of the five. The response was straightforward and honest. Sonnet 5 pointed out the real issue: having three months of money but needing four months to meet our goal is a problem. It then shifted the focus to finding paying clients before quitting, not after. The month-by-month plan was clear and matched my actual situation. The "what NOT to do" section was direct and helpful:
- Don’t quit until you have at least one signed contract
- Don’t spend money on branding, logos, or tools before proving someone will pay you, and
- Don’t skip having a written scope or contract.
This answer shows respect for the person asking the question. It shows the lower hallucination and sycophancy Anthropic advertises actually feels like something, not just a benchmark row.
Editor's note
After five tasks, I can confidently say that Sonnet 5 is not trying to beat Opus 4.8; it's trying to make you stop reaching for it. I can see myself using Sonnet 5 over Opus 4.8 for a lot of my future tasks. Sonnet 5 is no Opus 4.8 or Fable 5, but it is a powerful model in its own right. For most day-to-day knowledge and automation work, it is good enough for a lot of users. I used Sonnet 5 high, but you can use Max for even better results. If you use Cowork as much as I do, I think it could be a good replacement for Opus 4.8 and can save you some usage tokens.
As always, these were my results on my prompts. Yours will differ, so test Sonnet 5 yourself with your resource files and run similar tests yourself.
💡 For Partnership/Promotion on AI Tools Club, please check out our partnership page.
