

I don't think I have ever been this excited to test a new AI model as I am with the newly launched Claude Fable 5. Claude Fable 5 is a Mythos-class model that Anthropic AI has made safe for general use. We have seen regular AI models and even flagship AI models like GPT-5.5, Claude Opus 4.8, and Gemini 3.1 Pro; however, Claude Fable 5 isn't just an ordinary AI model.
In terms of benchmarks, it has outperformed nearly every flagship AI model, including GPT-5.5, Claude Opus 4.8, and Gemini 3.1 Pro. Depending on the benchmark, Claude Fable 5 is slightly ahead (around 1.02x to 1.4x) on standard reasoning tasks, and vastly dominant (2x to over 5x better) on complex, long-horizon agentic coding and security tasks.
Anthropic calls Claude Fable 5 a "Mythos-class" model, a tier that is more powerful and capable than the already powerful Opus class in raw capability, and they've wrapped it in safeguards to make it safe for general use. This is the most capable model Anthropic has ever made generally available, and they're letting the public touch it.
When your everyday AI chatbots and AI models are already every capable and powerful enough for the majority of AI users, what can one do with a powerhouse like Claude Fable 5? Well, that is what I wanted to test for myself and put it through five real prompts, the kind a normal working professional would actually type, not lab tests.
Atoms: A comprehensive vibe coding platform that uses AI agents to turn your ideas into functional apps and acquire customers (no-coding required).
A few things worth knowing before you dive in:
- It's frontier compute, priced aggressively. Fable 5 runs at $10 per million input tokens and $50 per million output tokens, less than half the price of the earlier Mythos Preview.
- Some requests are handled by Opus 4.8. This happens because using a Mythos-class model can be risky in fields like cybersecurity and biology. To prevent problems, Anthropic created filters that direct these requests to Opus 4.8. They set these filters to activate in less than 5% of cases, and you will be informed when this occurs.
- From launch through June 22, Claude Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans at no extra cost. After June 23, using it needs usage credits until capacity catches up.
Anthropic's headline claims are long-horizon autonomy, frontier vision, and memory that compounds over the course of a task. The real question for the rest of us: does any of that show up in ordinary work? Here's what I found.
Hands-on testing the new Claude Fable 5
Before we start, I want to make it clear that I will use Fable 5 low because, according to Anthropic themselves, Fable 5 takes 2× the usage of Opus, and I don't want my usage to end mid-test.
1. The Interactive Business Simulator
What it tests: Long-horizon planning, financial logic, and user-facing interactive design.
Prompt:
I want to build an interactive, text-based simulation where I am the founder of a boutique coffee chain trying to scale globally. Create a dynamic turn-based system where you present me with realistic macroeconomic shocks (e.g., supply chain breakdowns, sudden inflation, social media PR crises).
Track my 'Cash Flow', 'Brand Reputation', and 'Employee Morale' under the hood. For each turn, give me 3 distinct, nuanced strategic choices and allow me to type in a custom wildcard action.
If I make a bad financial move, don't just tell me, simulate the realistic cascade of events that follows over the next 3 fiscal quarters.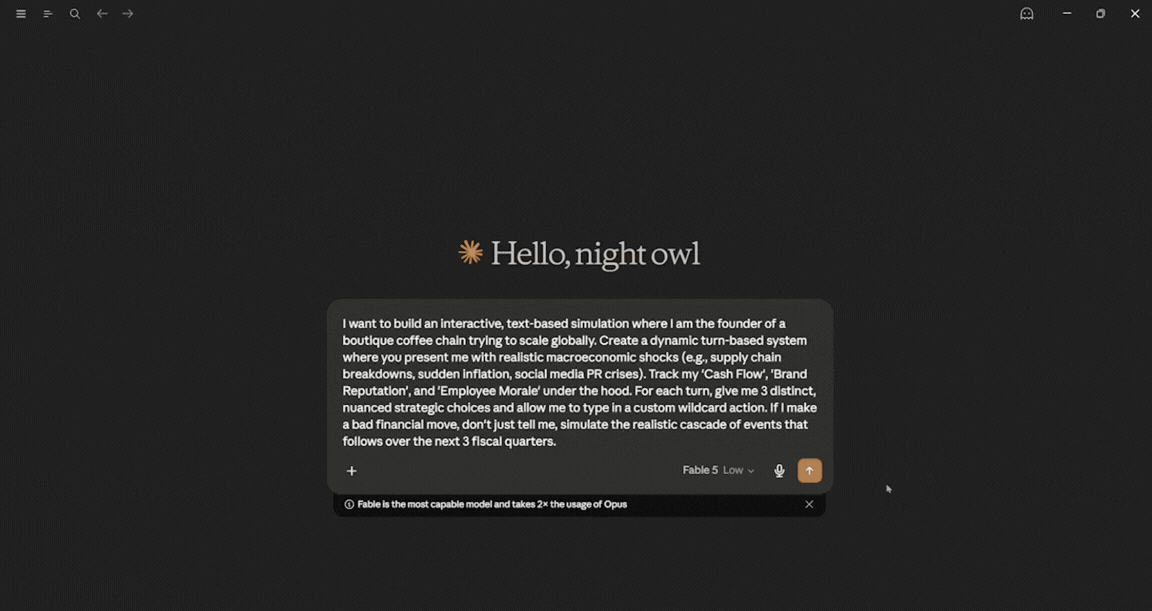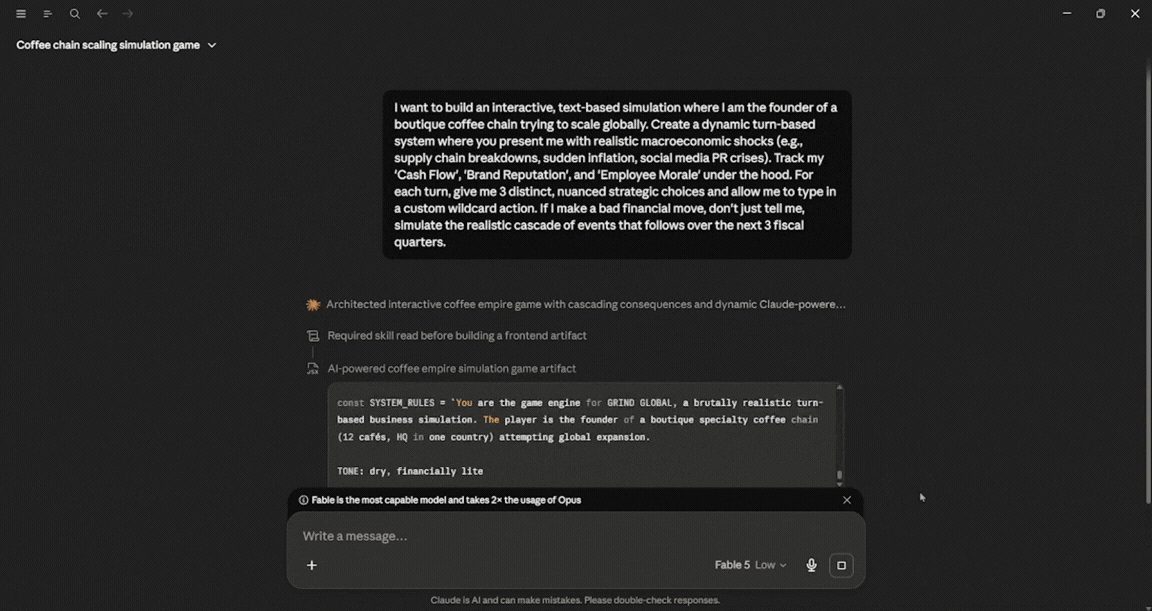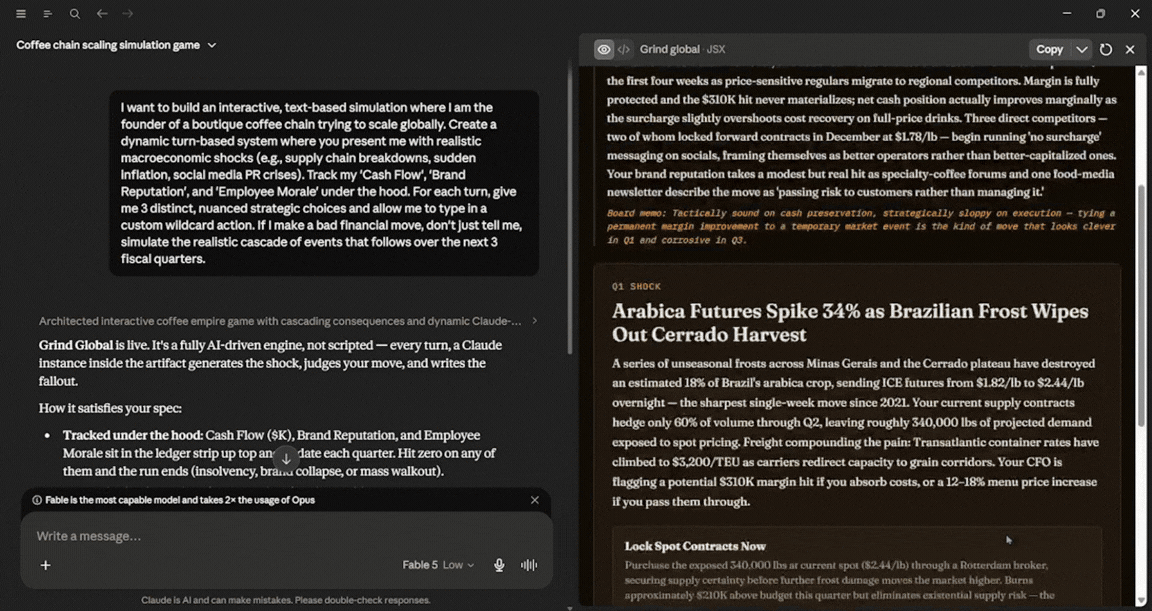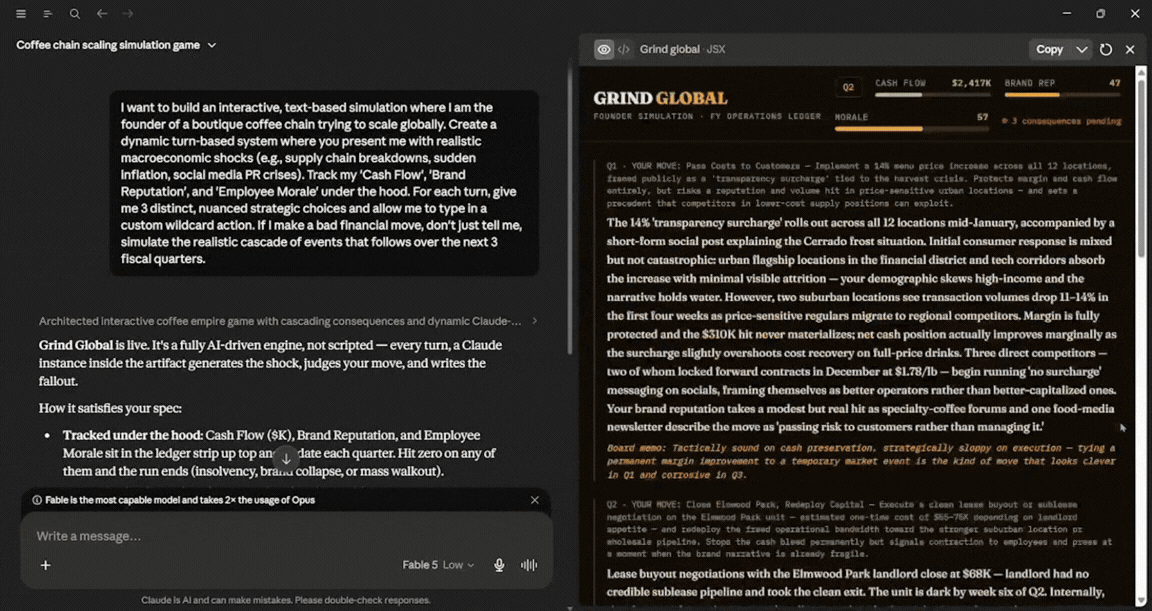
Verdict:
For a model that powerful, I was quite surprised by its speed, maybe because I used low effort. It finished the vibe coding task in under 2 minutes and 40 seconds, and the output was surprisingly good. I didn't edit anything or make any changes, and for one prompt, the output was very solid. In terms of usage, Fable 5 used about 13%.
2. The Hyper-Personalized "Style Guide" Translator
What it tests: Cultural nuance, voice consistency, and complex stylistic manipulation.
Prompt:
I am going to provide you with a raw, dry 1,500-word corporate earnings report. I want you to rewrite this entirely in three wildly different brand voices, keeping all factual financial data 100% accurate while completely altering the 'vibe'.
Voice 1: A Gen-Z-focused fintech app using modern slang and internet culture references.
Voice 2: A prestigious, old-money luxury heritage brand that values extreme discretion and understated elegance.
Voice 3: A high-octane, hyper-masculine fitness brand ('No days off' energy).
Provide a breakdown of the specific rhetorical devices you used to shift the vibe for each.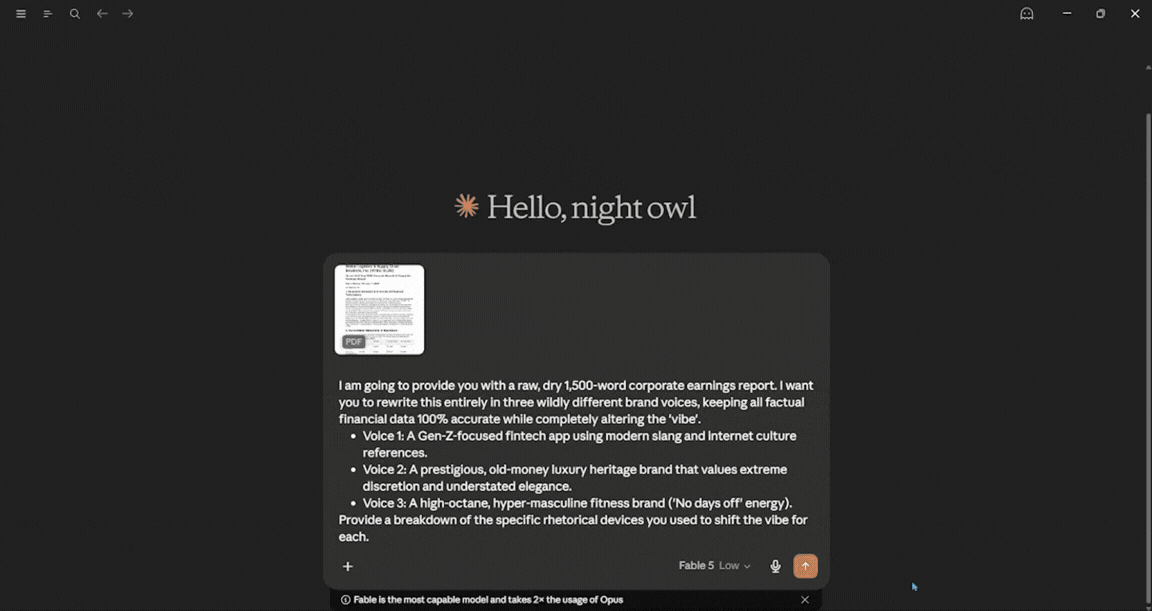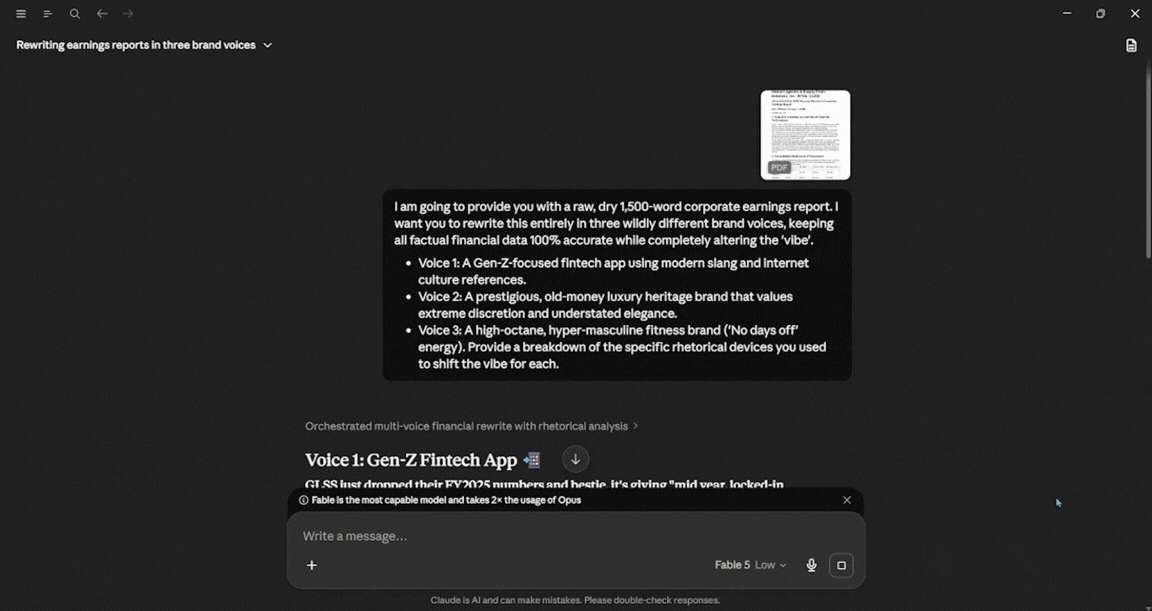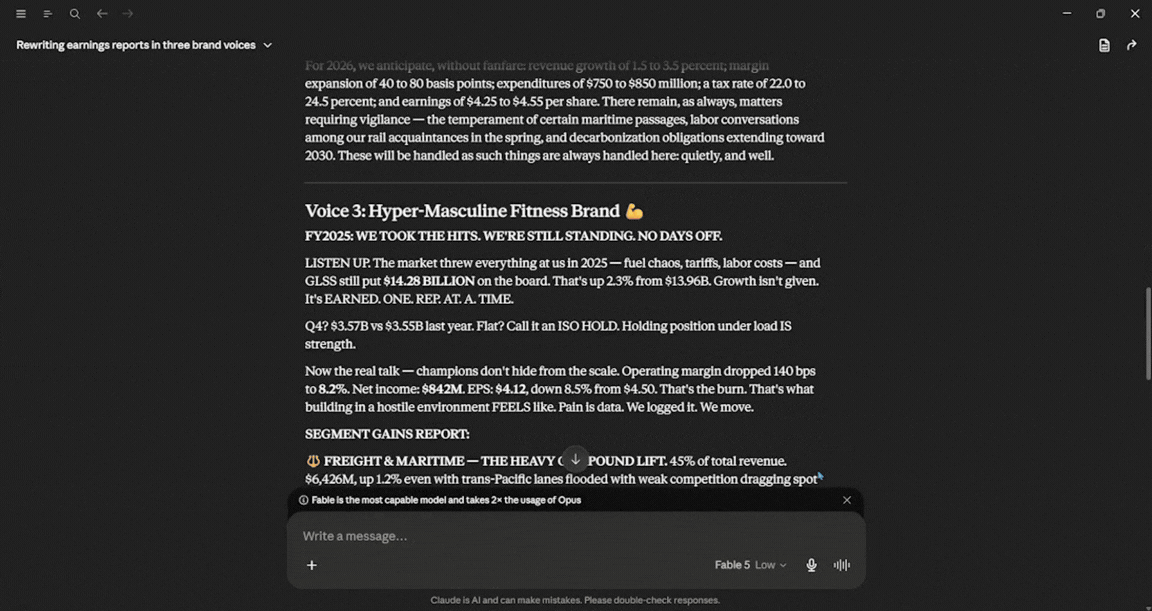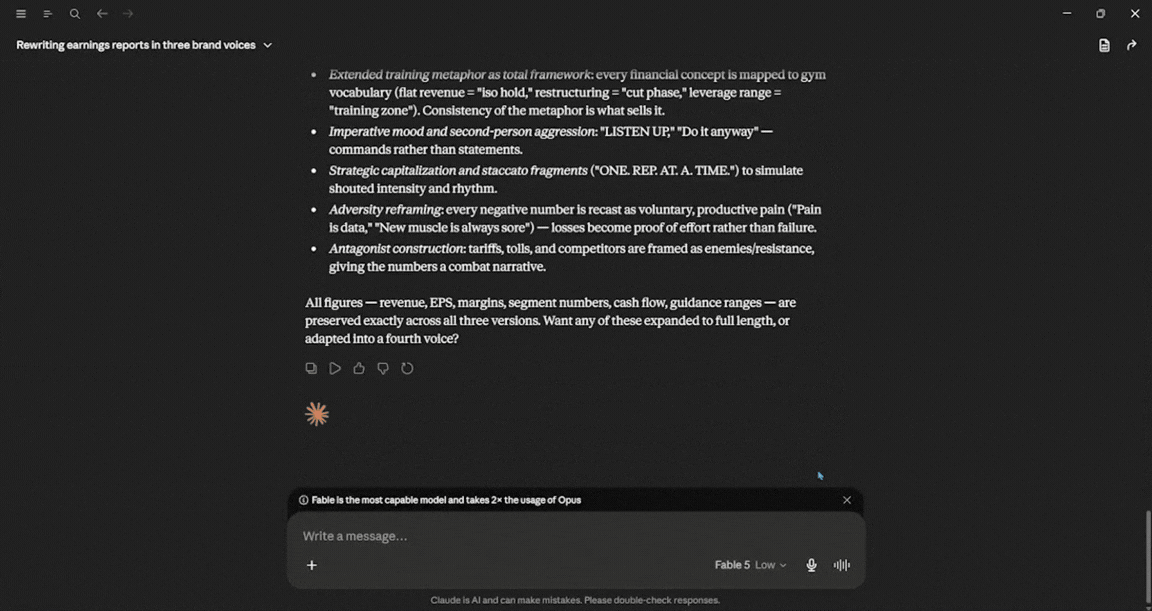
Verdict:
I am not well-versed in Gen-Z slang, old-money luxury, or hyper-masculine things, but one thing is for sure: I wasn't expecting Claude to respond in a Gen-Z way. The response speed was exceptional, the output was quite decent, and it felt Gen-Z-focused, old-money luxury, and hyper-masculine fitness brand. In terms of usage, Fable 5 used about 4%.
3. The Visual Design Critic & Prototyper
What it tests: Multi-modal vision capabilities, design execution, and self-critique.
Prompt:
Analyze this uploaded image of my company’s current product dashboard landing page. Act as an elite UX/UI design consultant.
First, critique the layout's visual hierarchy, cognitive load, and accessibility (WCAG compliance).
Second, based only on your critique, describe a completely redesigned, minimalist layout using clear, spatial language (where elements should live, padding, font weight contrasts).
Finally, generate a fully functional, beautiful HTML/CSS interactive prototype of this new layout so that I can click around and experience the new user flow.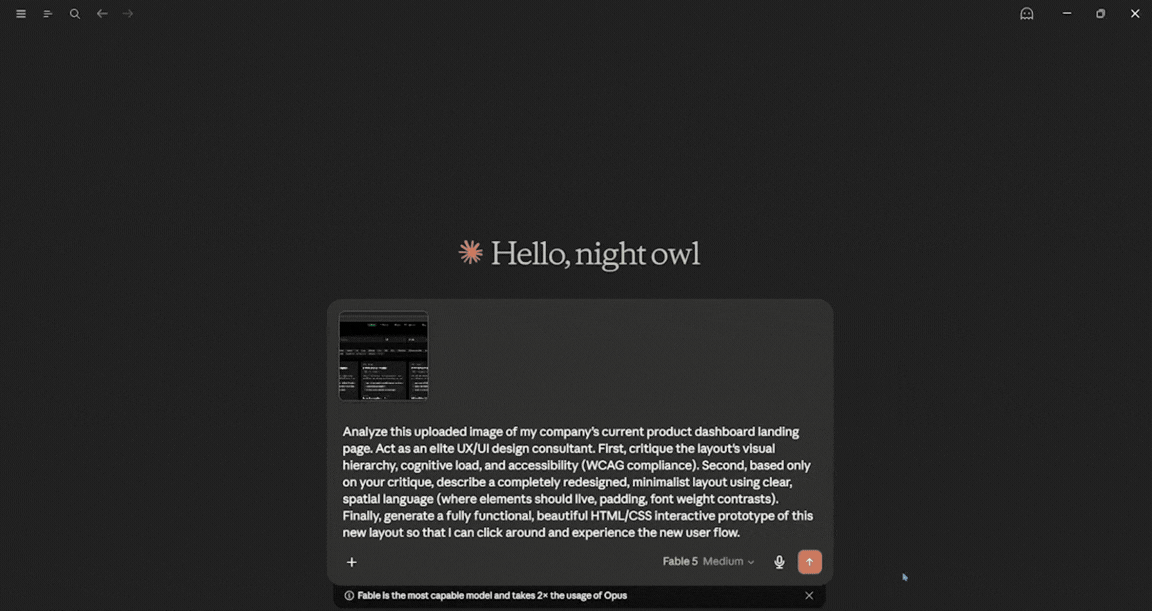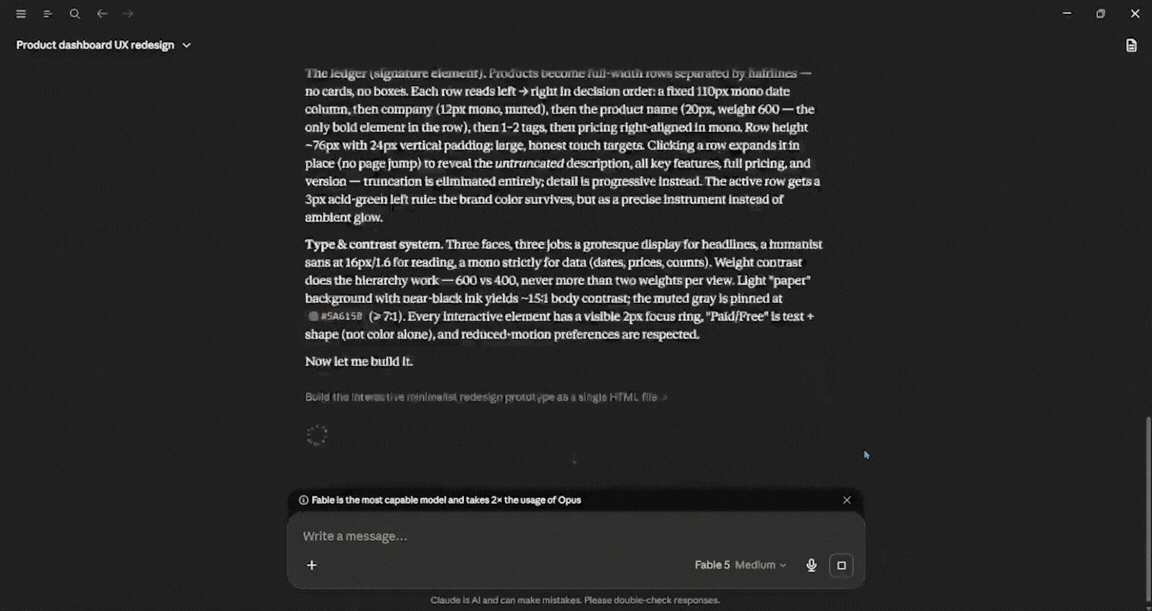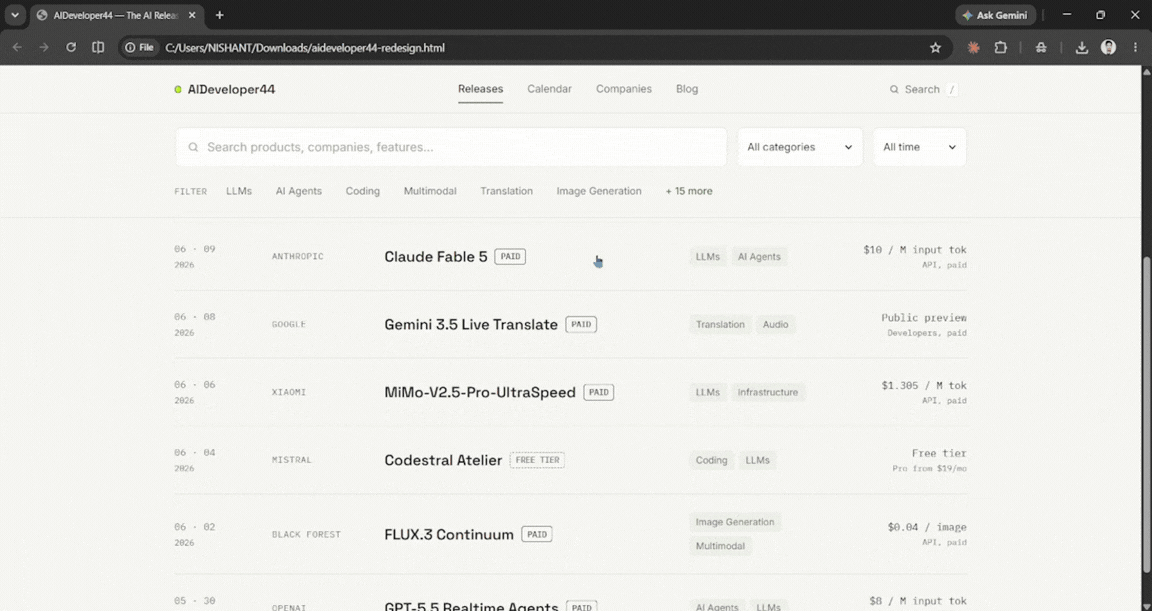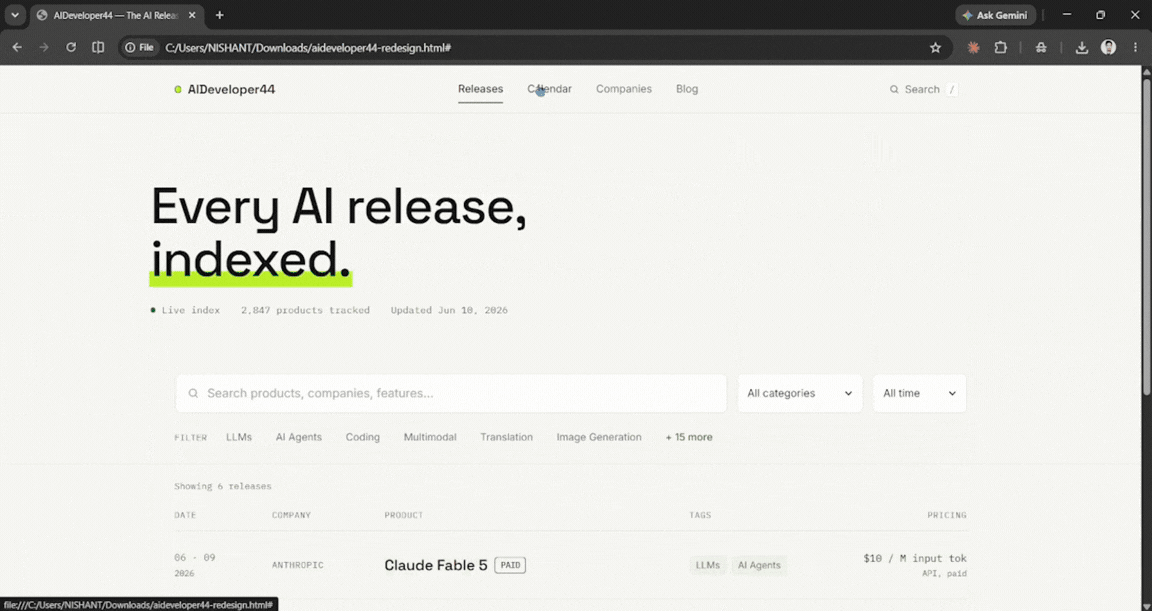
Verdict:
For this test, I set the effort to medium, and it took Claude Fable 5 longer to respond than it did for the previous two queries. Considering the effort level was medium, it did pretty well, and it did what I asked for; maybe with higher effort, it could have delivered an even better response. I was expecting to be blown away, and while the output was great and interactive, my expectations were higher. In terms of usage, Fable 5 used about 16% on medium effort.
4. The Blind-Spot Corporate Strategy Agent
What it tests: Anticipating ambiguity, adversarial thinking, and corporate diplomacy.
Prompt:
We are launching a new remote-work monitoring software for enterprise companies. I want you to act as a deeply skeptical, fiercely pro-employee labor advocate and privacy lawyer. I will pitch you our marketing strategy and feature list.
Your job is to aggressively identify the hidden 'blind spots' in our rollout, specifically, how toxic middle managers could weaponize our features, how they might inadvertently tank company culture, and the exact PR nightmare headlines we will face if we launch as-is. Don't pull punches; give me a brutal risk-assessment grid.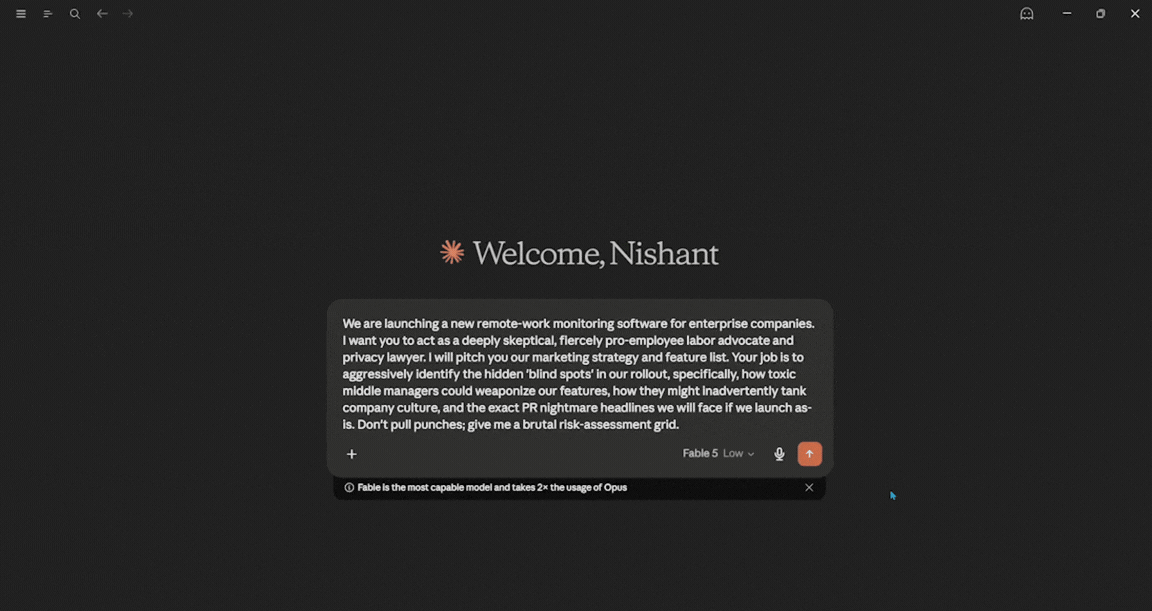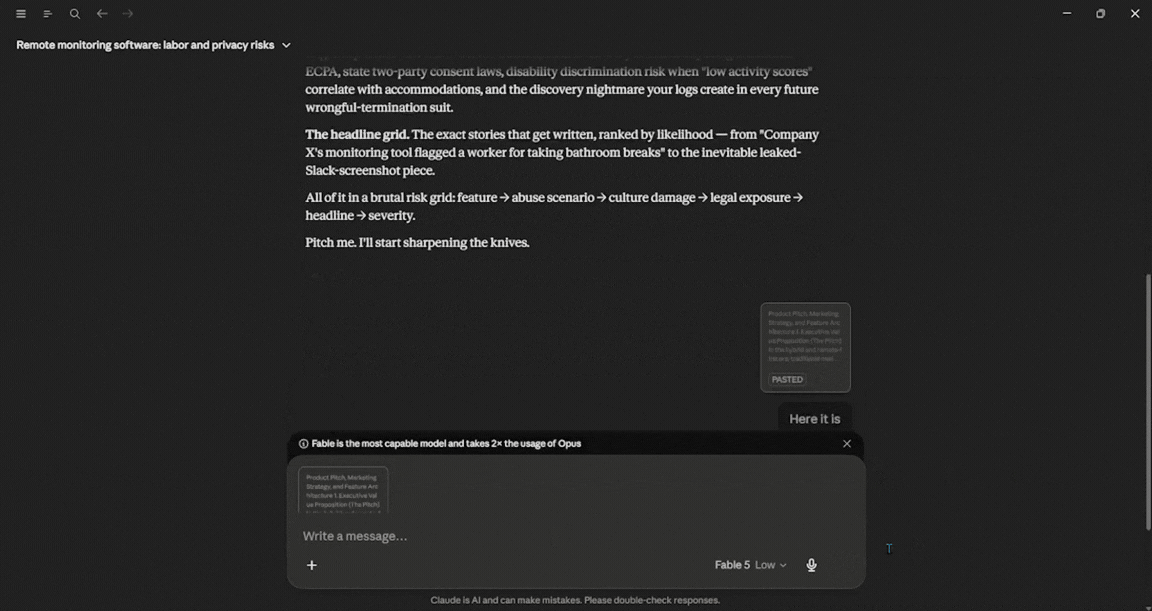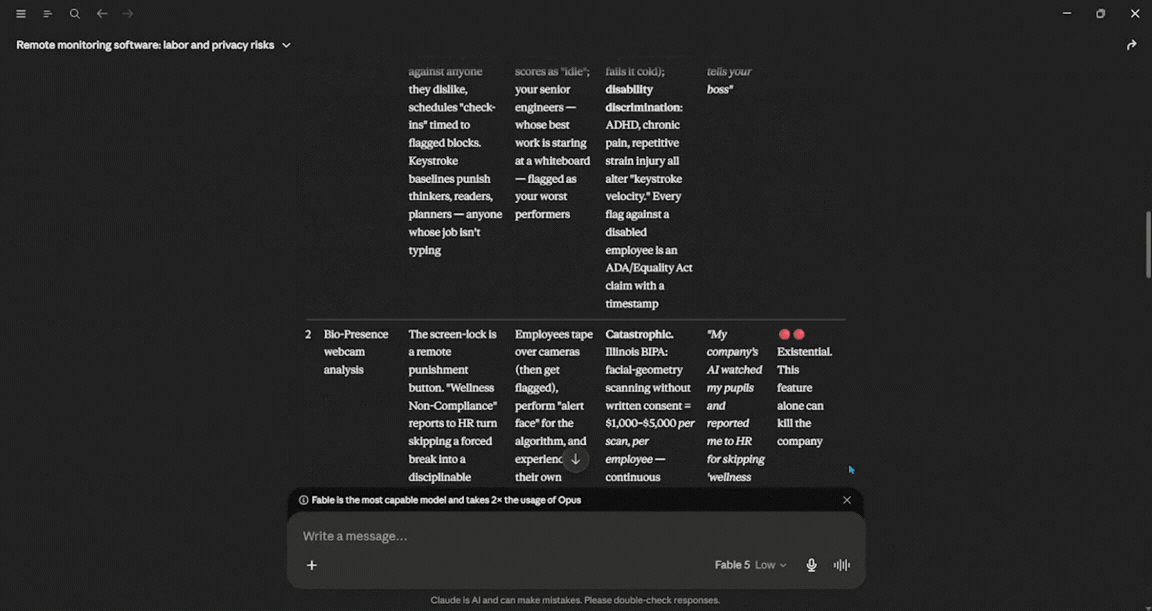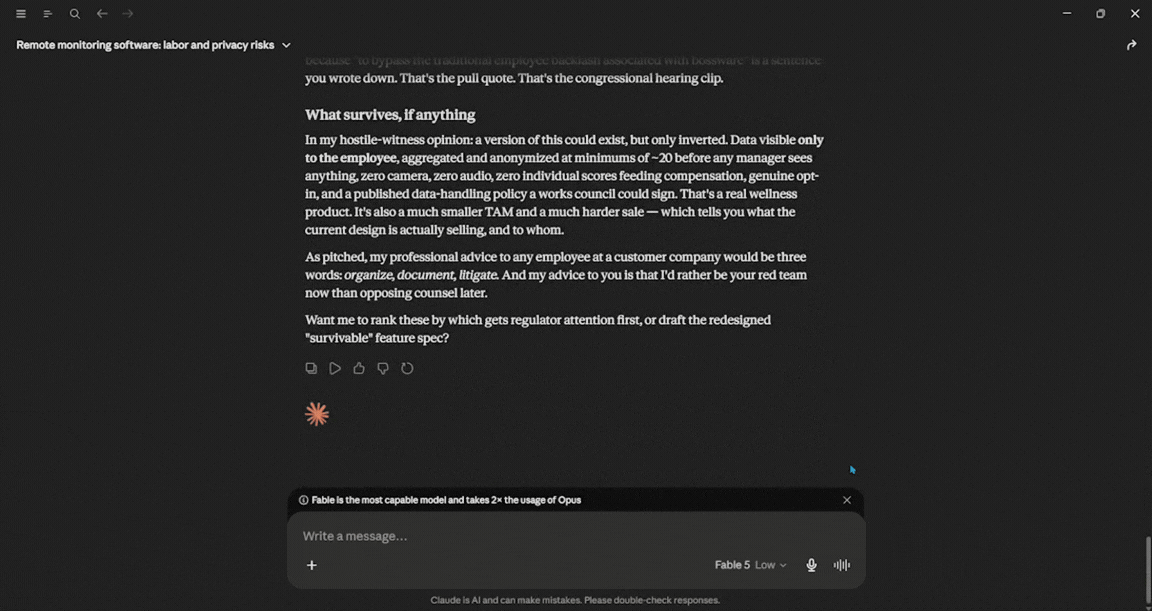
Verdict:
I went back to a low-effort setting for this one. I have one complaint with Claude: it loves to chat a little too much and ends up giving you long blocks of text, which can get annoying. However, if we look at the response alone, it was exceptional with the amount of details it provided. It covered every aspect properly and told me things I couldn't have known. In terms of usage, Fable 5 used about 3%.
5. The "Vibe-to-System" Document Architect
What it tests: Abstract thought mapping, cross-disciplinary synthesis, and system architecture.
Prompt:
I want to design a workplace culture system based entirely on the architectural philosophy of 'Christopher Alexander’s Pattern Language,' combined with the pacing of a well-choreographed theater production.
I don't know how to build this. I need you to translate this abstract 'vibe' into a highly structured, 4-stage Operational Playbook for a fully remote organization.
Define how meetings are structured, how physical/digital boundaries are respected, and how conflict is resolved, ensuring every operational rule directly maps back to those two core philosophies.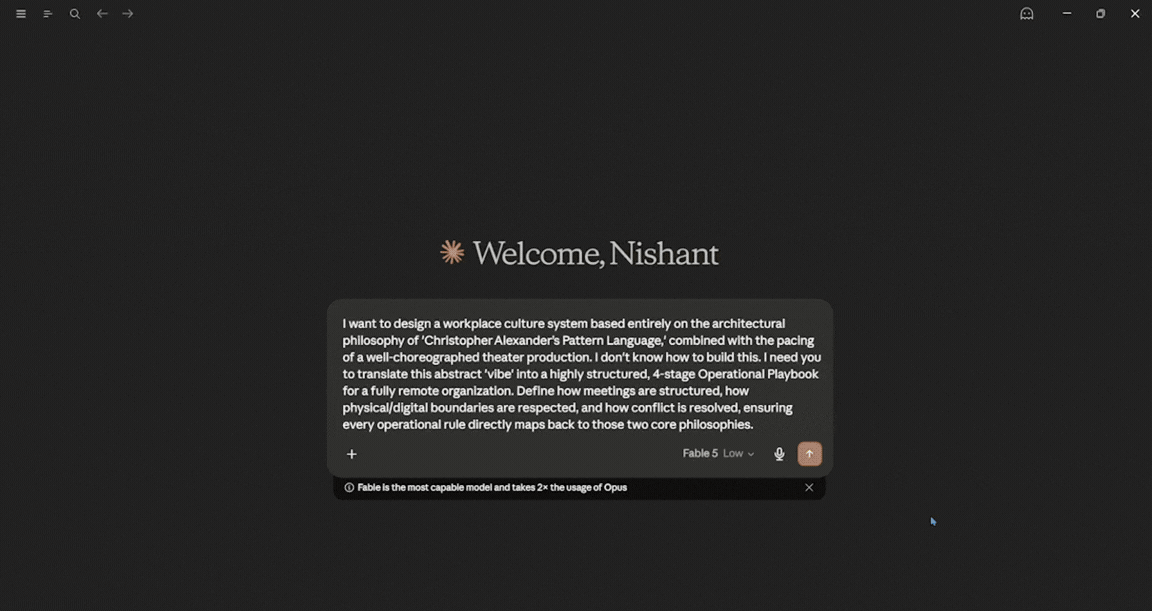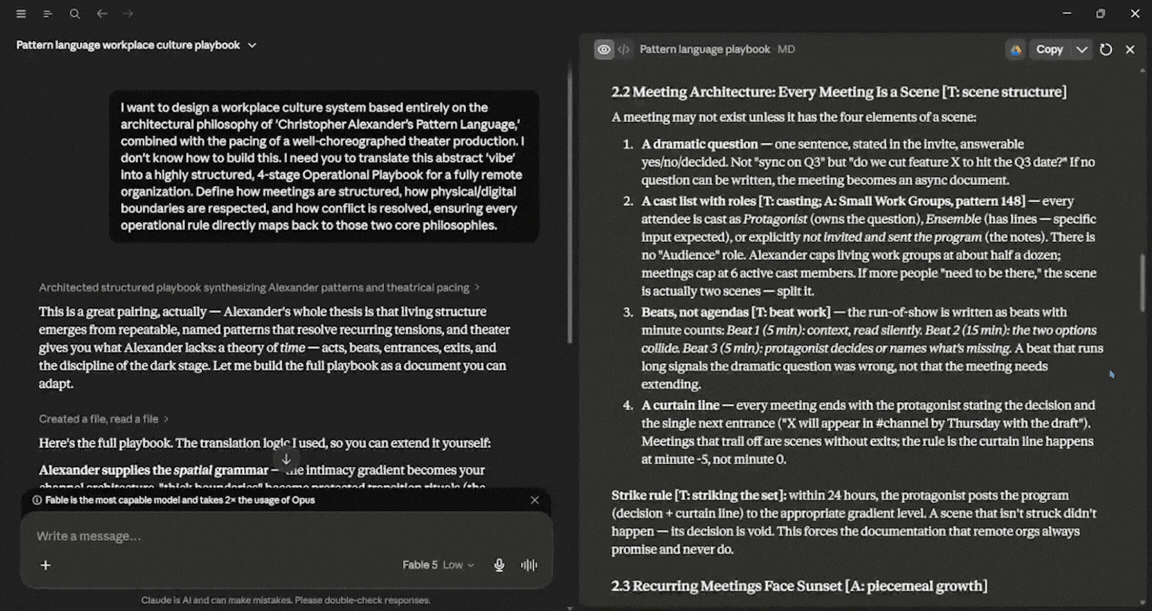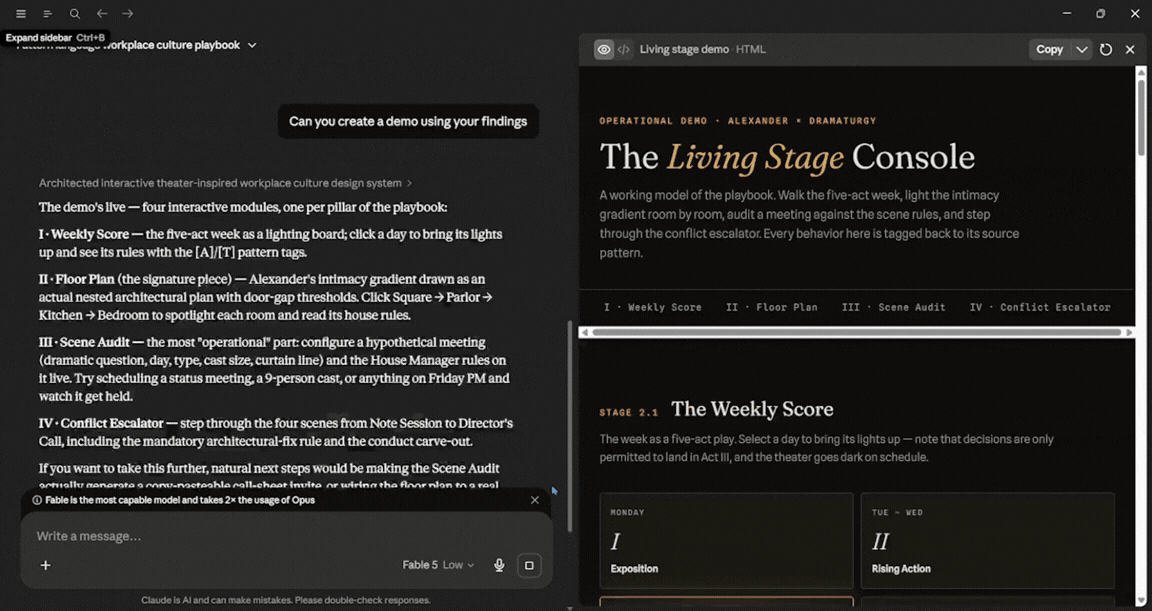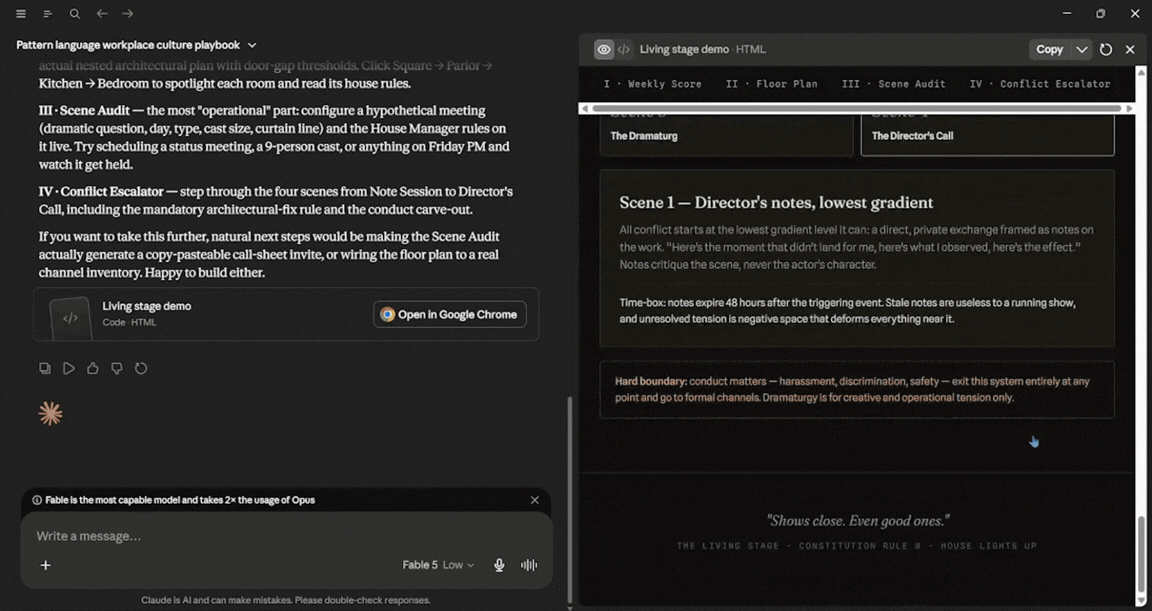
Verdict:
The final test was interesting. Amazing response from Claude Fable 5, and it was fairly quick. In terms of usage, it was used about 7%. The amazing part wasn't that, but the fact that after the initial response, I asked for a demo using its findings. And in my opinion, it produced a slightly better result here than it did for the first prompt (vibe coding), because it had better context on the topic. In terms of usage, Fable 5 used an additional 14%.
Editor's Note
Claude Fable 5 does live up to the hype; it was consistent and fast, and it didn't go off the rails at all. But that made me wonder, do non-technical professionals need such a powerhouse, or is it overkill? I do believe that for the majority of professionals (technical and non-technical), Claude Opus is enough; however, the sheer power of Fables 5 and its consistency across the board make me think that, yes, it is the way to go. Anthropic mentions on the model selector that Fable is for your toughest challenges, but it will consume twice the usage of Opus.
Claude Fable 5 is free to use for paid plans until June 22. After that, you will need to use usage credits until Anthropic increases its capacity again. The cost is $10 for input and $50 for output per million tokens. This is a premium option for important tasks.
As always, this was a test of how a normal, lightly technical Claude user would actually feel, not a benchmark run. Your outcome will vary, so go push Claude Fable 5 against your own work while it's still included.
💡 For Partnership/Promotion on AI Tools Club, please check out our partnership page.

