

OpenAI has released its new GPT-5.5 AI model, calling it its smartest and most intuitive-to-use model yet and its first fully retrained base model since GPT-4.5. The company has framed it as a new class of intelligence for real work and powering agents. The AI model is built to understand complex goals, use tools, verify its own output, and carry out tasks all the way to completion.
GPT-5.5 is rolling out to Plus, Pro, Business, and Enterprise users inside ChatGPT and Codex. A higher-accuracy variant, GPT-5.5 Pro, is limited to Pro, Business, and Enterprise subscribers. As of the writing of this article, the API access is coming very soon. The GPT-5.5 matches GPT-5.4's per-token latency in real-world tasks, so the intelligence jump comes without a speed tax.
What Can the GPT-5.5 AI Model Do
OpenAI's stance is that you can give GPT-5.5 a messy, multi-part task and trust it to plan, pick tools, check its own work, navigate ambiguity, and keep going.
The biggest gains show up in four areas:
- Agentic coding: You can write, debug, refactor, and ship full features inside Codex, with a better understanding of large codebases and failure modes.
- Computer use: The AI model can operate email, spreadsheets, calendars, and desktop software to finish real workflows end-to-end.
- Knowledge work: You can draft documents, build spreadsheets, research online, and analyze data.
- Early scientific research: ChatGPT-5.5 can also assist with technical workflows, including areas like drug discovery.
On benchmarks, the picture is strong but not a clean sweep.
- GPT-5.5 scores 82.7% on Terminal-Bench 2.0 (vs. 69.4% for Claude Opus 4.7 and 68.5% for Gemini 3.1 Pro).
- 35.4% on FrontierMath Tier 4, 78.7% on OSWorld-Verified, and 84.9% on GDPval.
- On SWE-Bench Pro, it hits 58.6%, below Claude Opus 4.7's 64.3%.
- GPT-5.5 Pro pushes 90.1% on BrowseComp for deep web research, ahead of Gemini 3.1 Pro at 85.9%.
In simple words, the new GPT-5.5 is excellent, often leading, occasionally second, and worth testing against your own stack.
5 Prompts to Stress-Test GPT-5.5's Intelligence:
1. Vibe-coding challenge
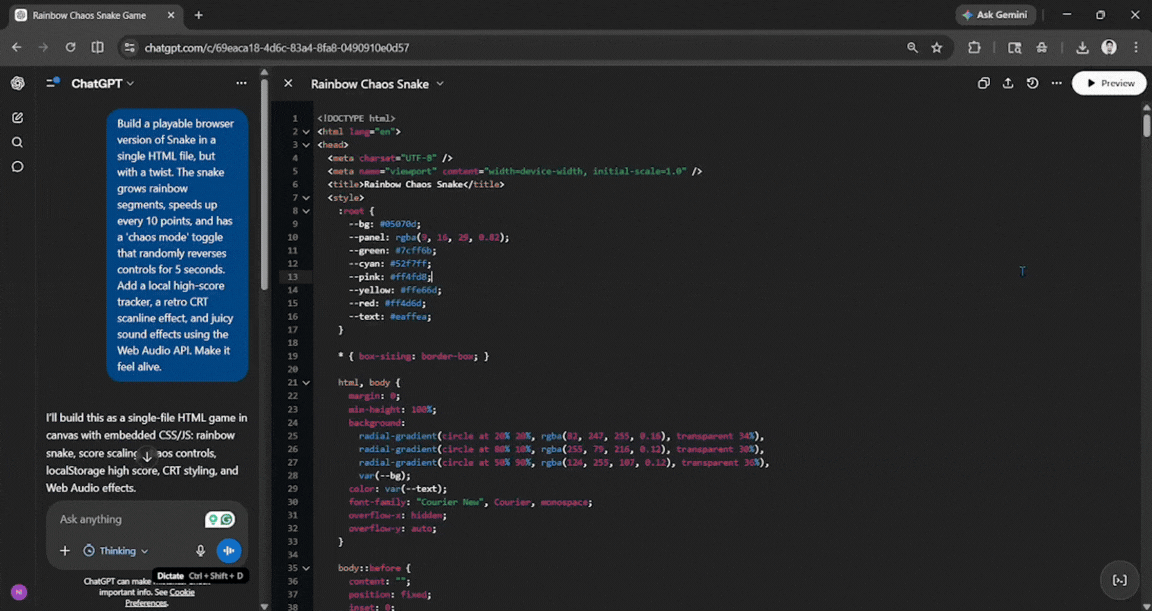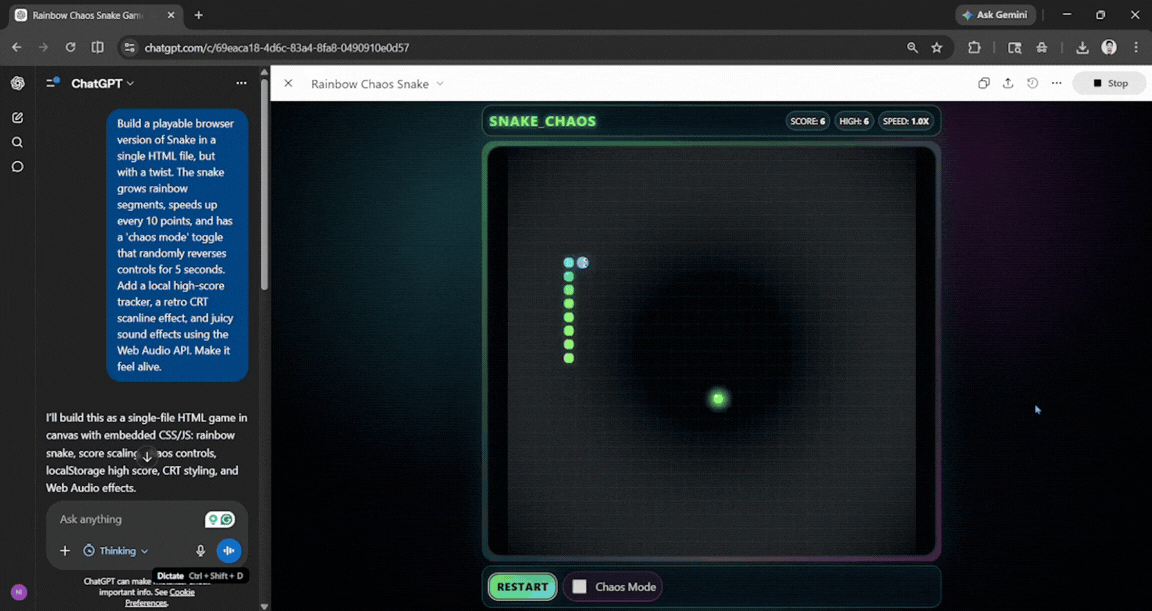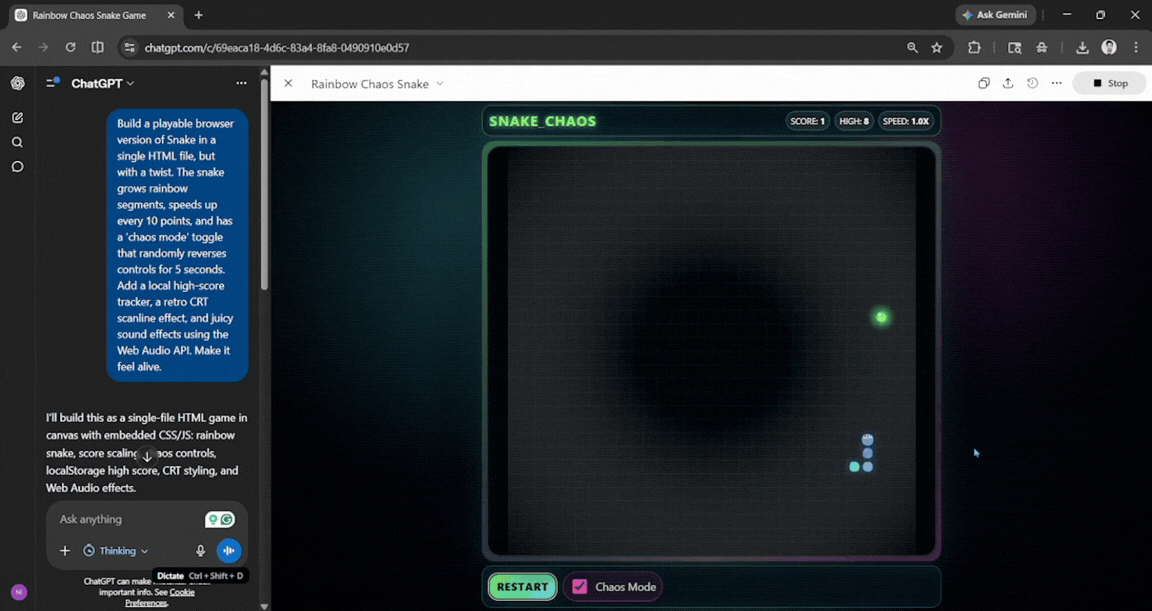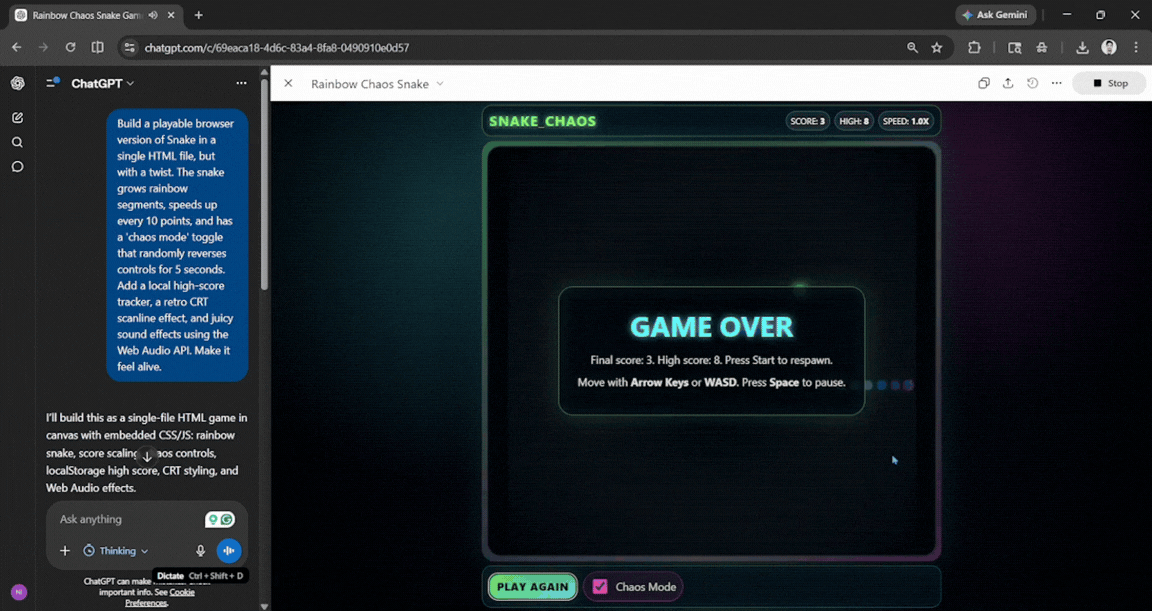
Prompt: Build a playable browser version of Snake in a single HTML file, but with a twist. The snake grows rainbow segments, speeds up every 10 points, and has a 'chaos mode' toggle that randomly reverses controls for 5 seconds. Add a local high-score tracker, a retro CRT scanline effect, and juicy sound effects using the Web Audio API. Make it feel alive.
Verdict:
The first draft was solid, but I couldn't see the bottom half of the board, so I had to ask ChatGPT to let me scroll down to see it. However, once it was done, the output was enjoyable and clean. It felt smooth and with no lag, and the chaos mode worked well.
2. Real-world knowledge work
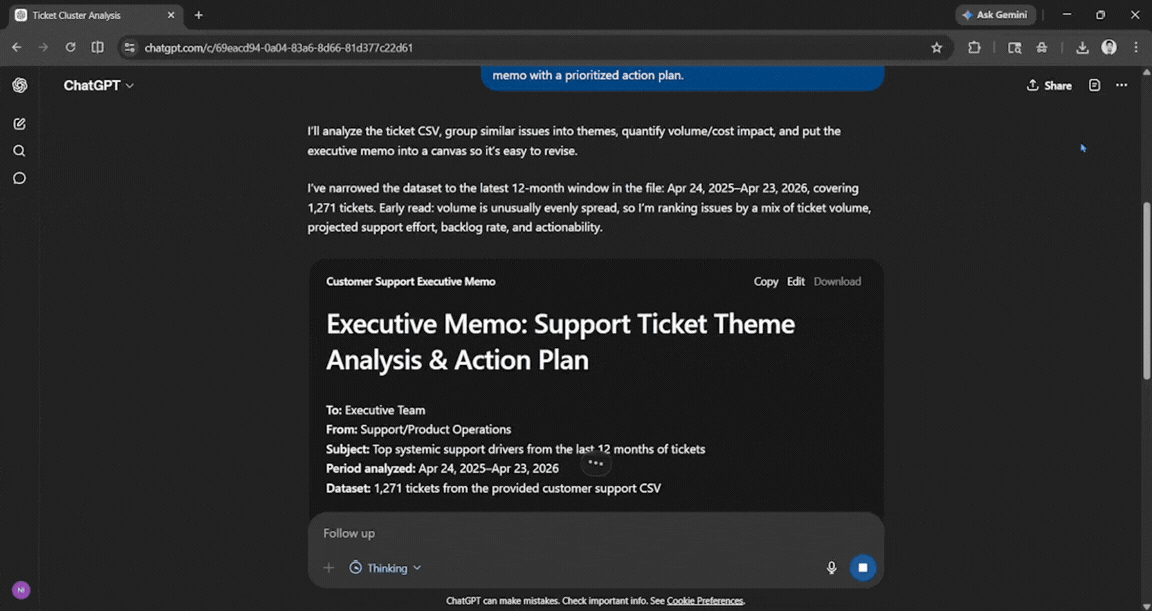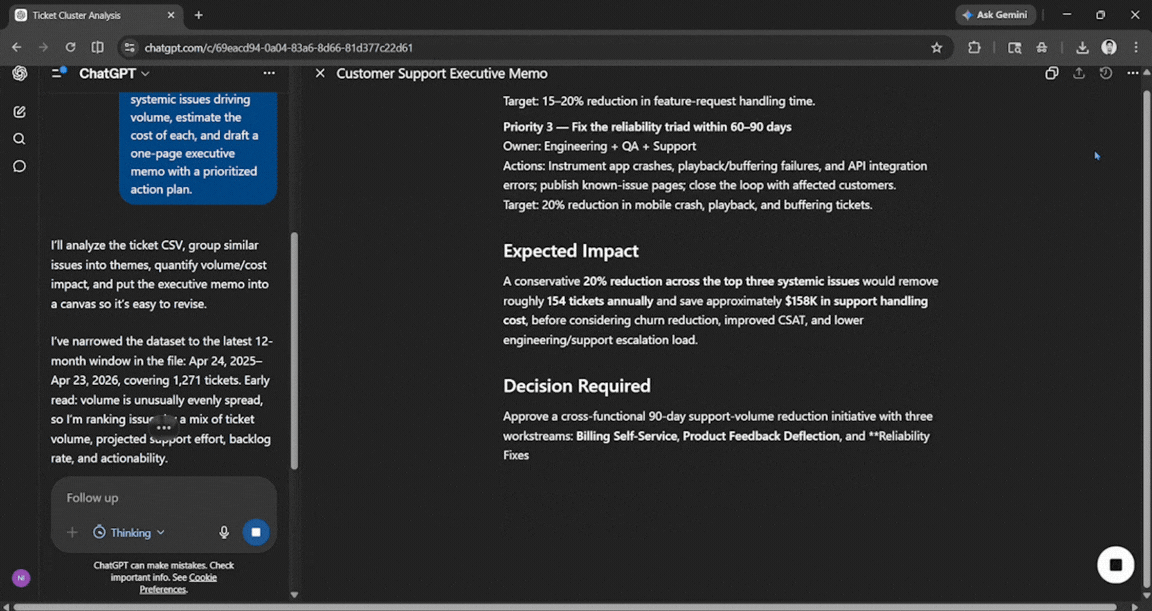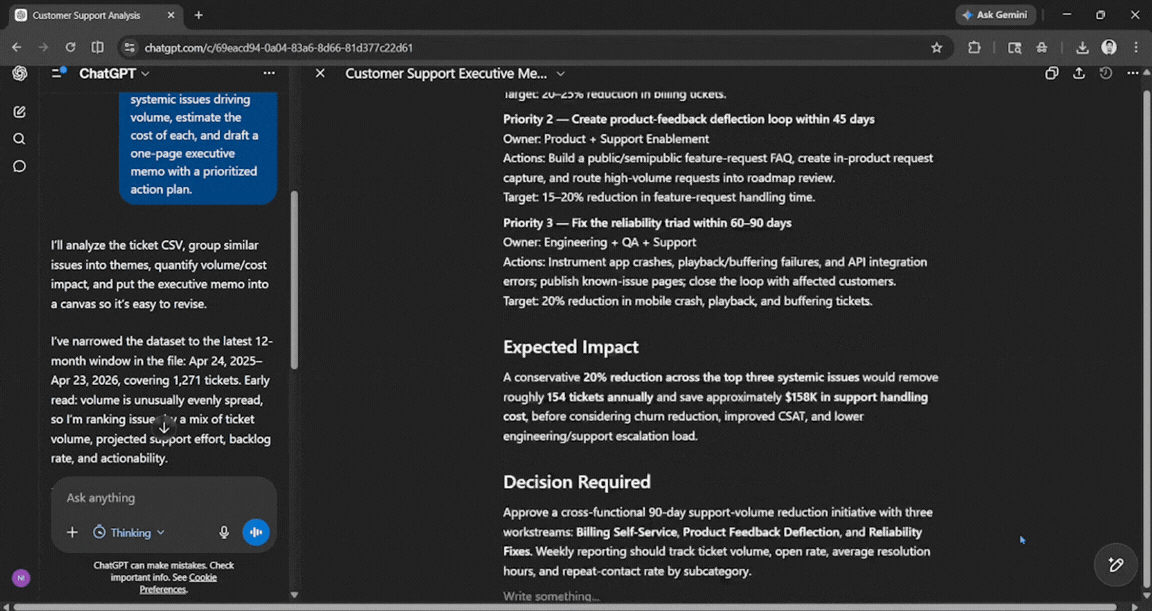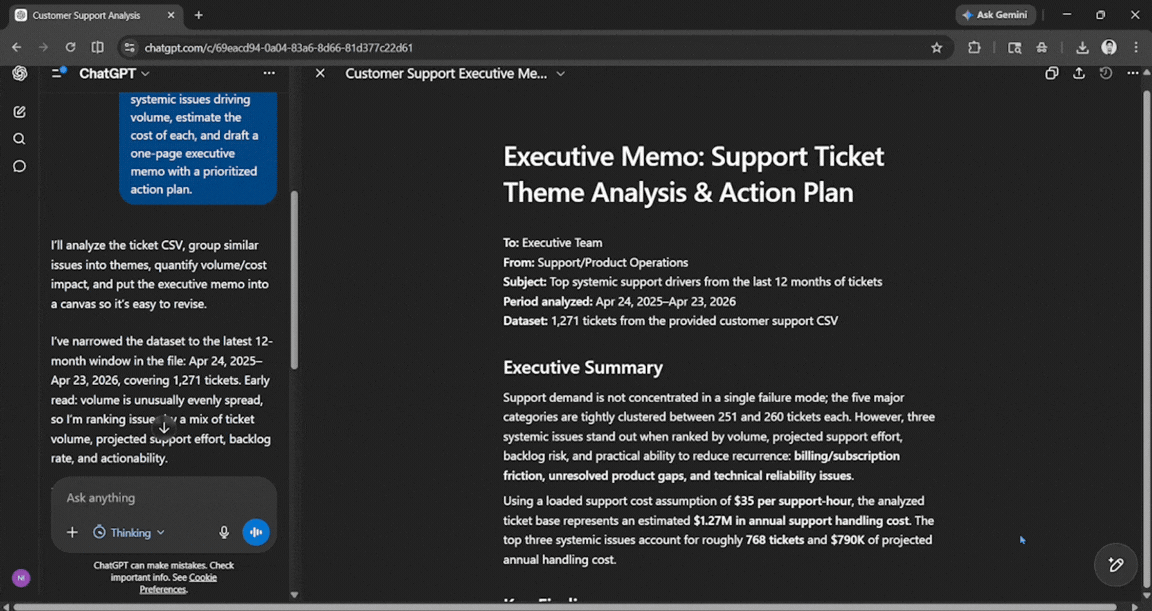
Prompt: Here is a CSV of our last 12 months of customer support tickets. Cluster them into themes, identify the top three systemic issues driving volume, estimate the cost of each, and draft a one-page executive memo with a prioritized action plan.
Verdict:
The output was very clean and professional. It was good enough for anyone who doesn't have time to go through an entire spreadsheet and needs the information quickly. Everything mentioned was easy to follow and understand.
3. Vibe coding a productivity tool
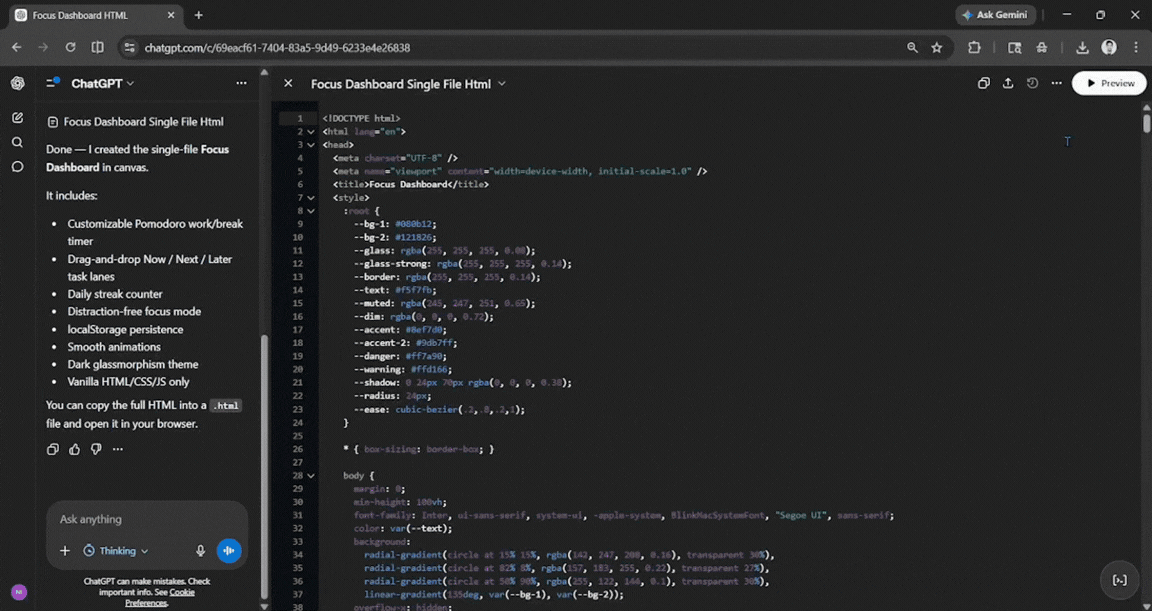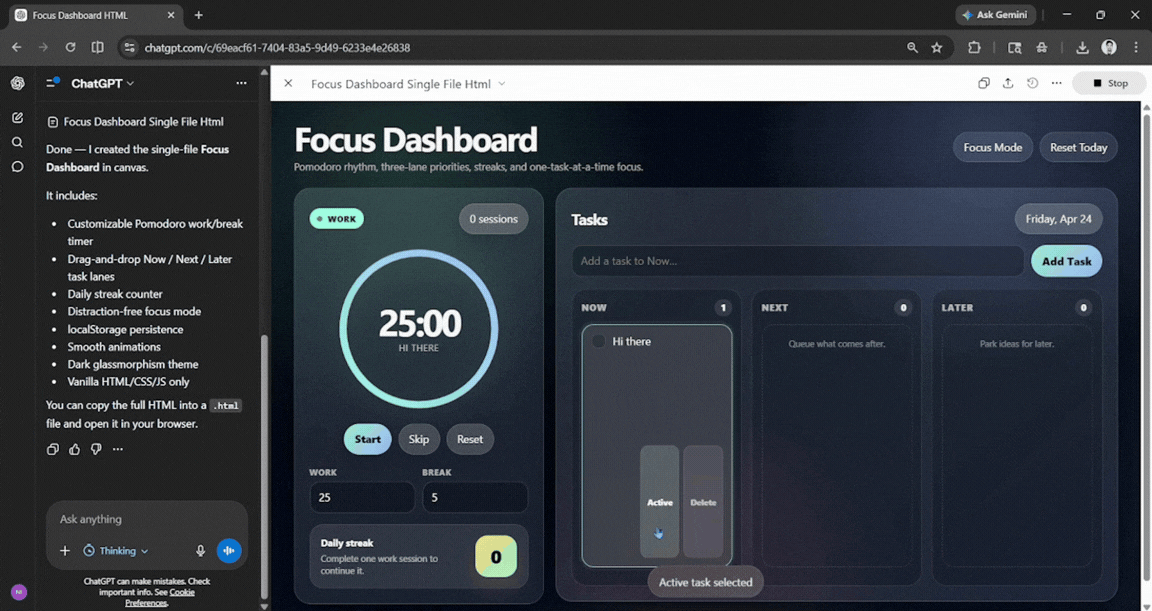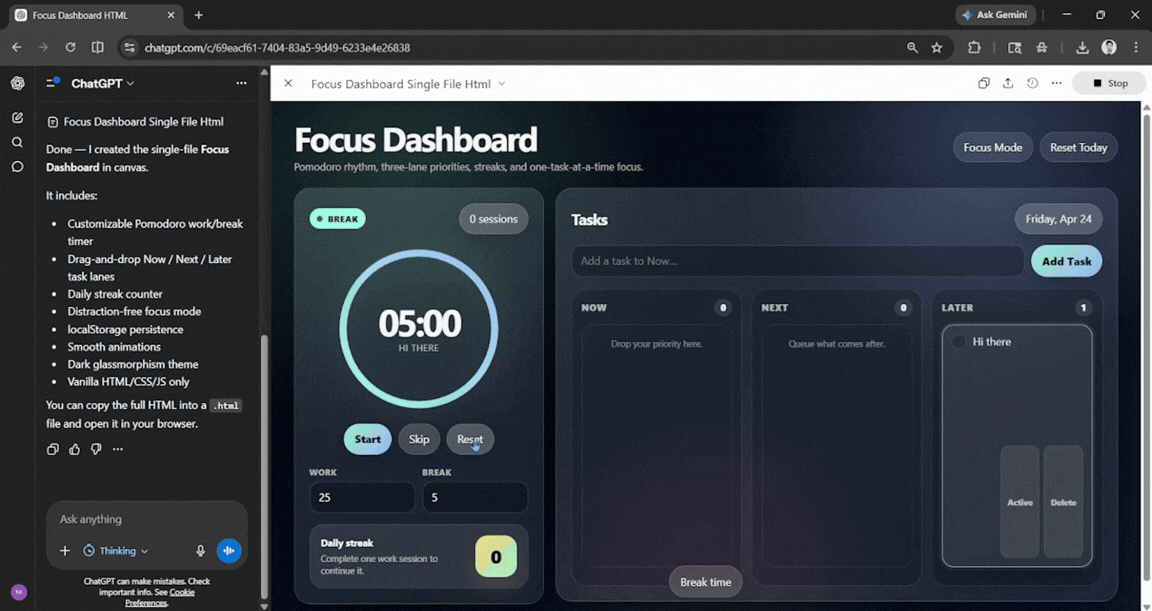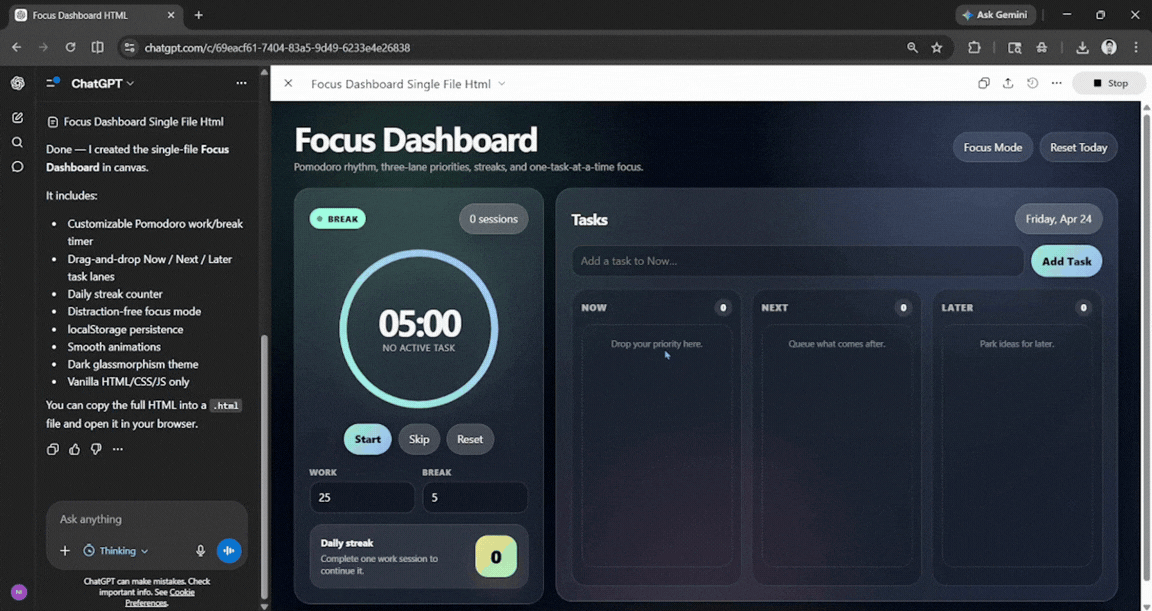
Prompt: Build a single-file HTML 'Focus Dashboard' I can open in my browser. It needs: a Pomodoro timer with customizable work/break lengths, a drag-and-drop task list grouped into Now/Next/Later, a daily streak counter, and a minimal distraction-free mode that dims everything except the active task. Use localStorage so my data persists, add smooth micro-animations, and style it with a clean glassmorphism dark theme. No frameworks, vanilla JS only.
Verdict:
The output was solid. ChatGPT stuck to the prompt and created what I wanted exactly the way I wanted. I didn't really need to make any tweaks, and everything worked smoothly.
4. Multi-tool agentic workflow
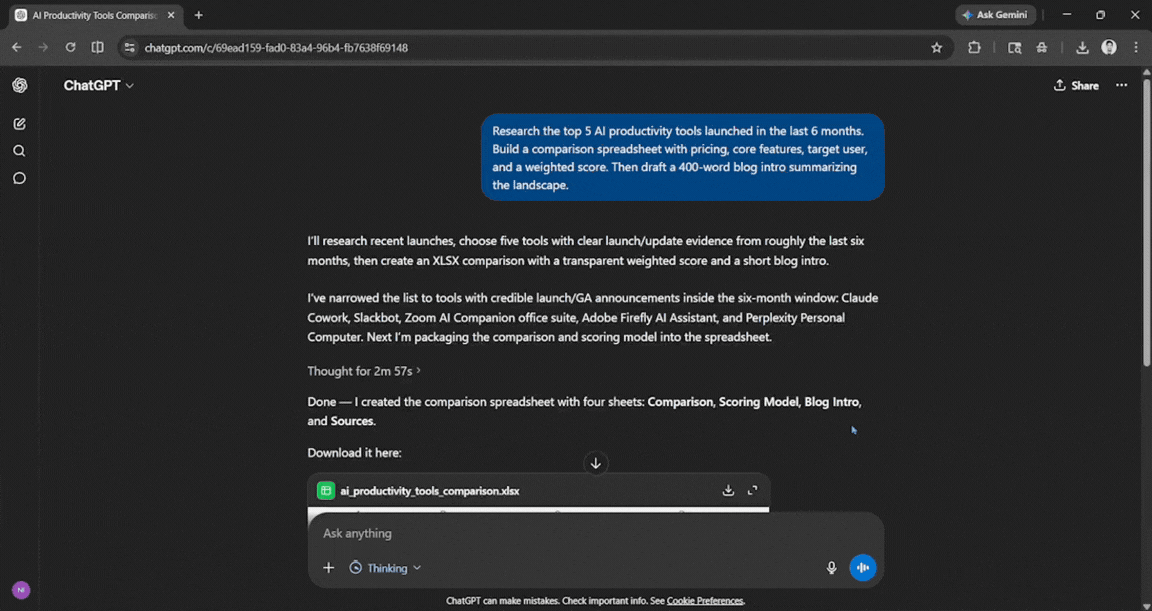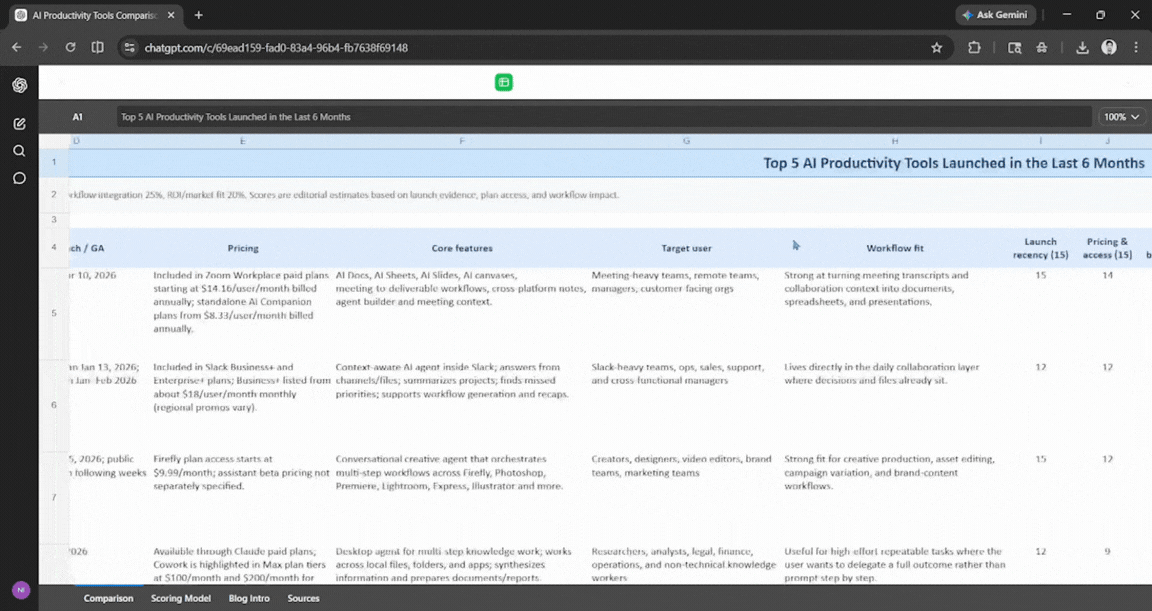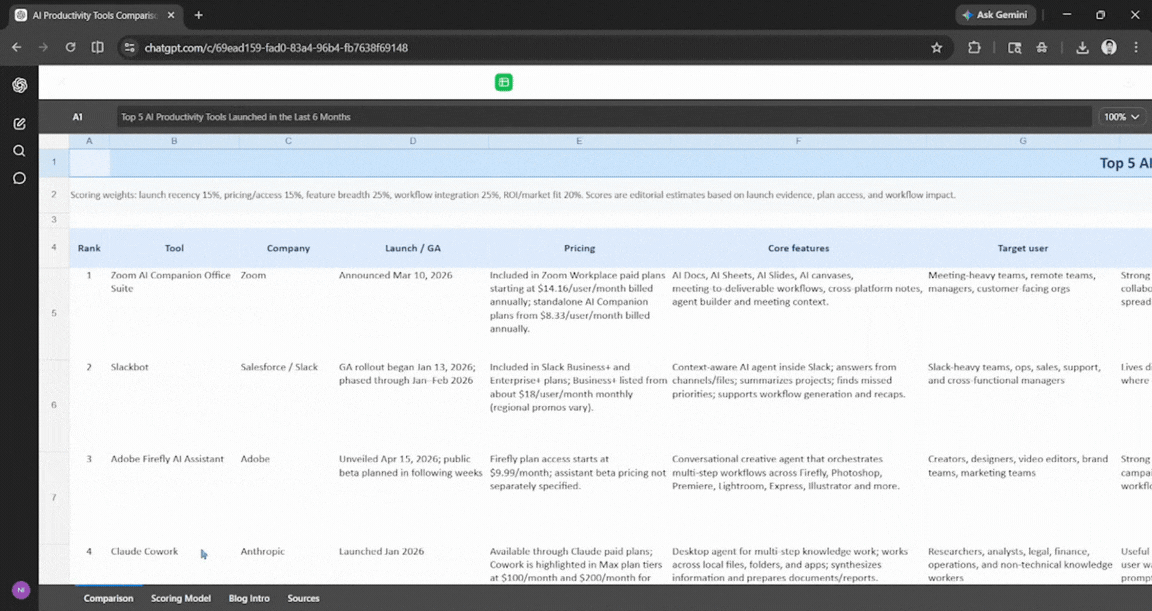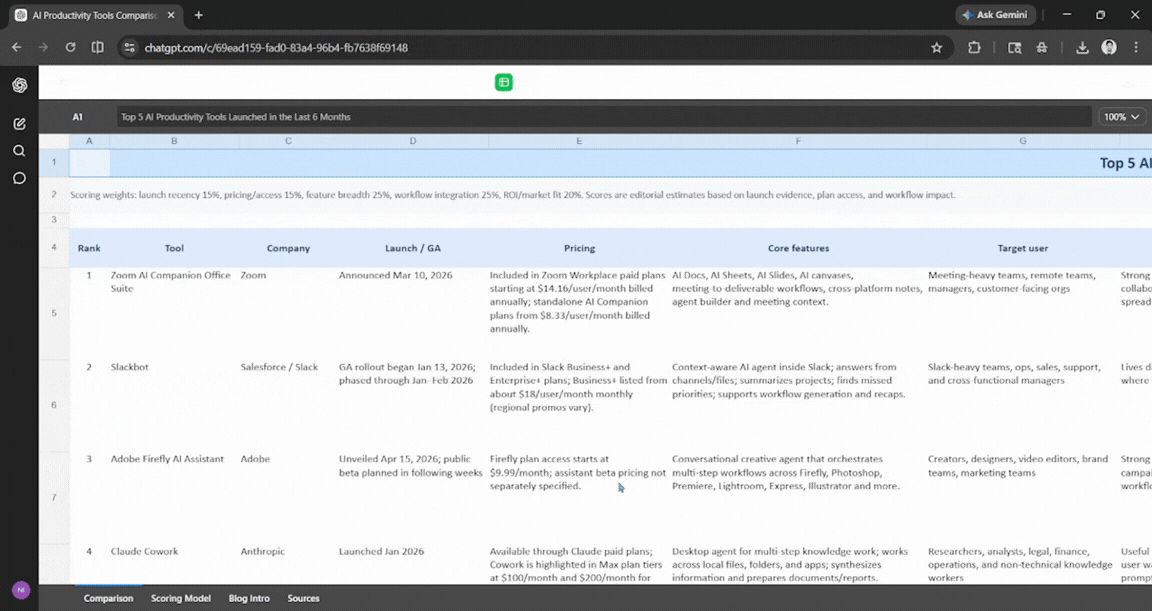
Prompt: Research the top 5 AI productivity tools launched in the last 6 months. Build a comparison spreadsheet with pricing, core features, target user, and a weighted score. Then draft a 400-word blog intro summarizing the landscape.
Verdict:
The output was solid, and it felt complete. ChatGPT spent a good few minutes completing this task, and the Excel file was simple and easy to follow. It had all the necessary information one would have needed, and what I asked for. It was surprisingly good.
5. Reasoning under ambiguity
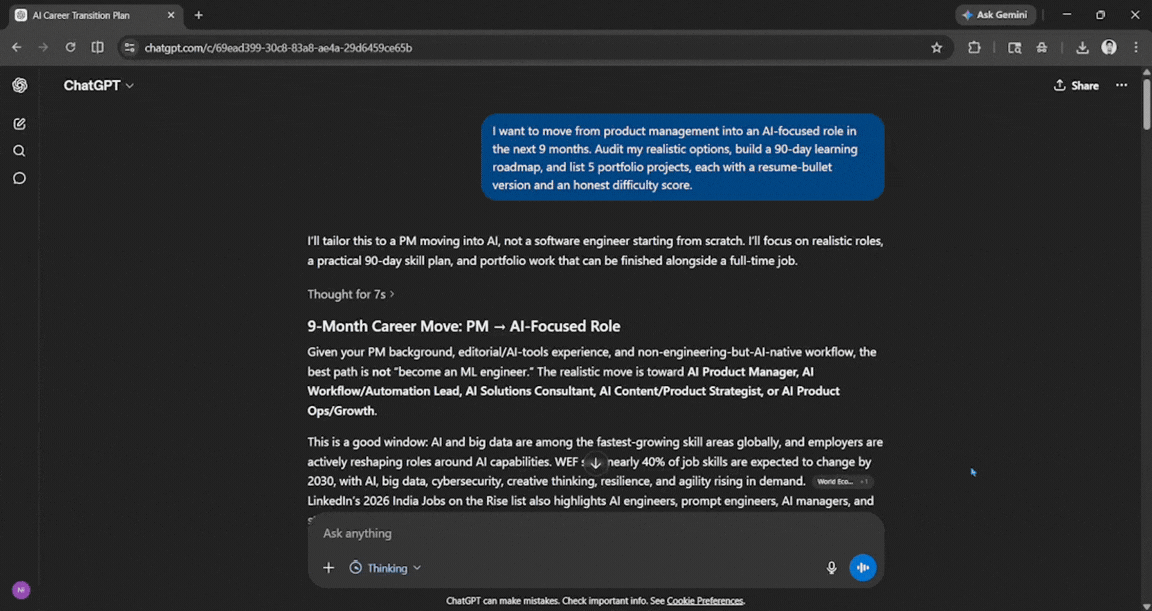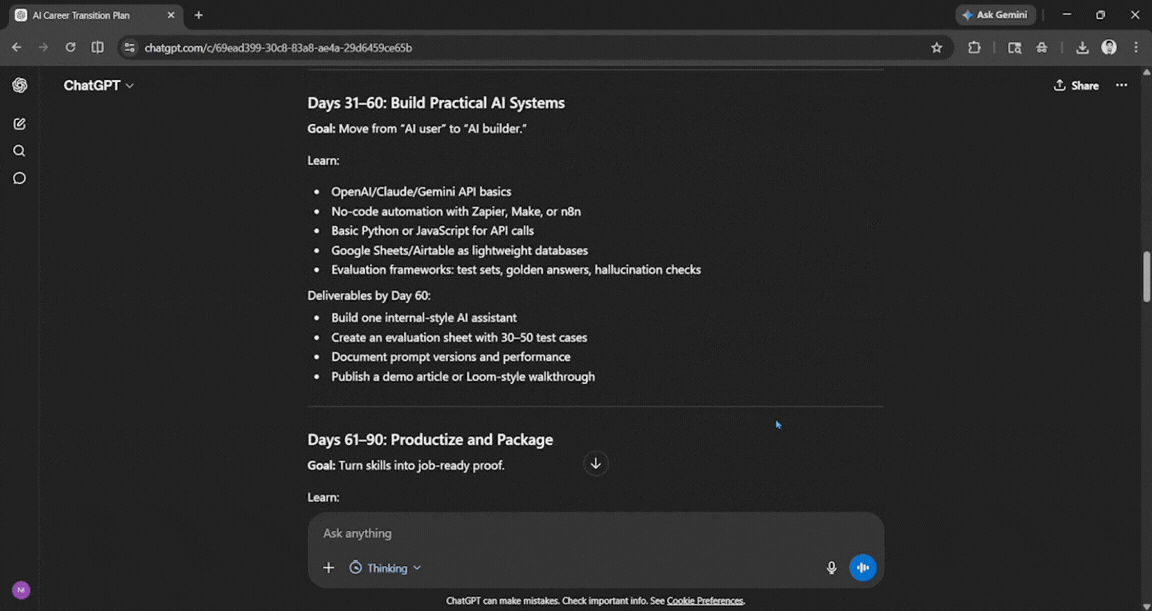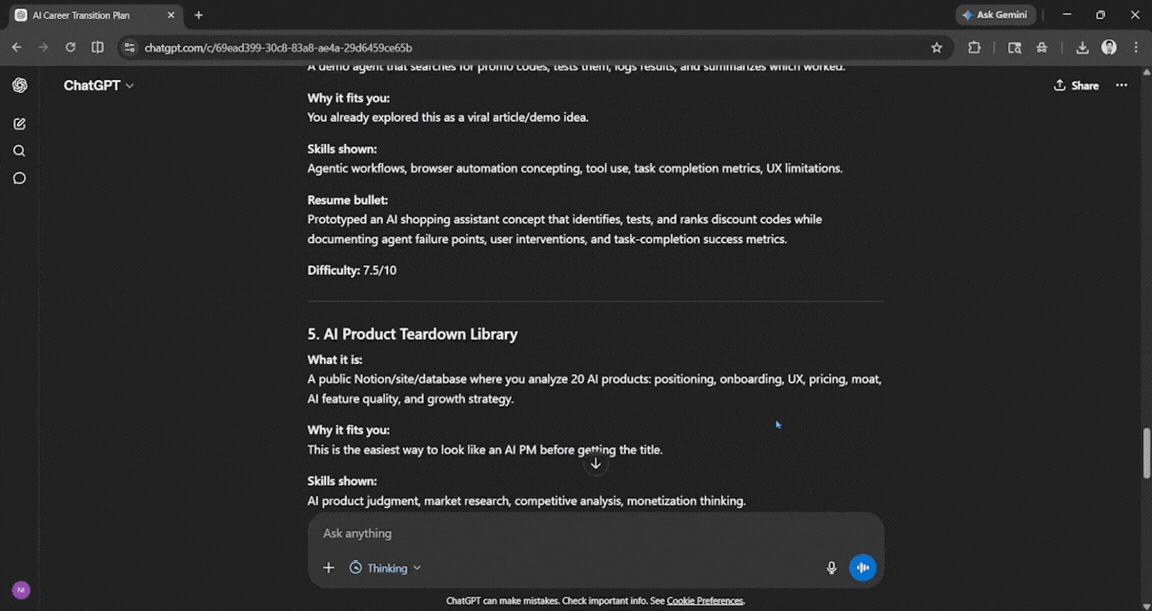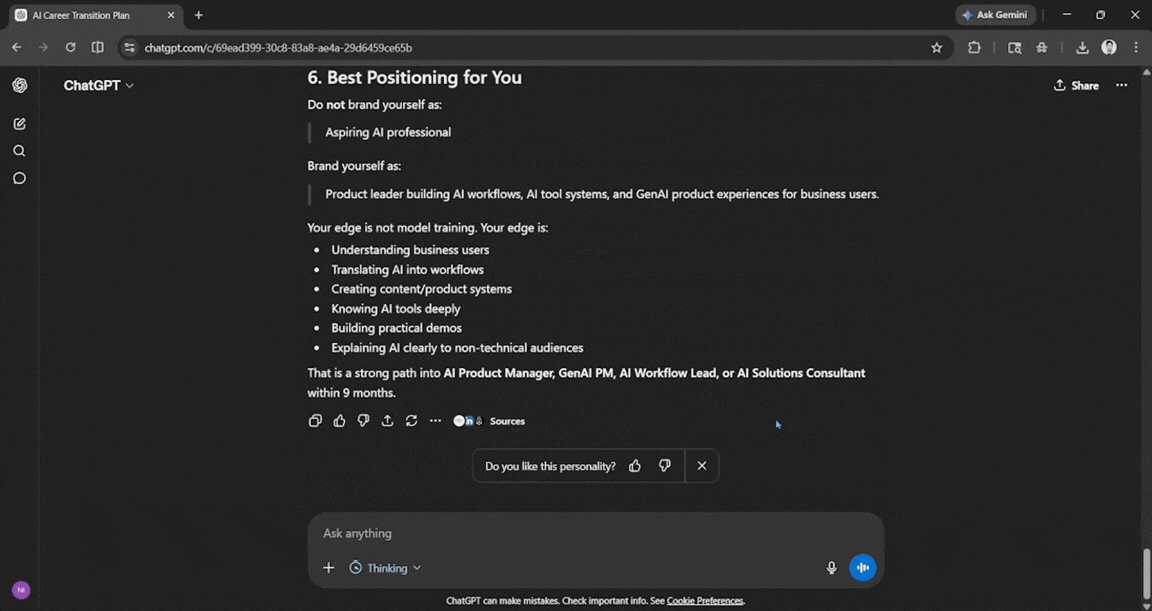
Prompt: I want to move from product management into an AI-focused role in the next 9 months. Audit my realistic options, build a 90-day learning roadmap, and list 5 portfolio projects, each with a resume-bullet version and an honest difficulty score.
Verdict:
This was one of the best answers I have received from ChatGPT in a long time. Yes, the above 4 were improved, but ChatGPT here used good logic and memory, showing how well it understands my capabilities and intentions. It offered a good breakdown based on what it knows about it, and it was impressive.
Editor's note:
GPT-5.5 is a meaningful step up for messy, multi-step work and a clear response to competitive pressure from Anthropic and Google. During my stress test, it performed really well apart from that one minor issue with the first output. One important thing to note is that if you want to use ChatGPT-5.5, you will need to turn on thinking mode, since GPT-5.5 Instant hasn't been released, and OpenAI is still using GPT-5.3 Instant.
This test was to show the improvements a regular non-technical to slightly technical ChatGPT user would experience. Your experience could be very different from mine, so test the new ChatGPT-5.5 yourself.
💡 For Partnership/Promotion on AI Tools Club, please check out our partnership page.

