

ChatGPT-5 has been called "smarter," "more reasoned," and "production-ready," but what does that actually mean when you put it under pressure in a real-world scenario? So, we decided to do it in this article. This is a hands-on ChatGPT-5 Extreme Test, where we use five prompts that push this powerful AI model by OpenAI on what matters in real work, i.e., precision, verification, and the ability to follow constraints without drifting. Instead of cherry-picked demos, we run the same structured challenges anyone can reproduce and compare.
Here's the plan:
- We hit Math with an exacting number-theory puzzle that forces full factor logic and self-checks.
- We test Science with a physics problem that requires a derivation, units, and real numbers.
- We try Vibe Coding by shipping a tiny, single-file planner that balances UX, accessibility, and persistence.
- We stress coding with a streaming 95th-percentile estimator—an algorithm you can't fake with toy arrays.
- And finally, we probe History with a sourced argument that rewards evidence over confident guesses.
Each prompt specifies strict output formats, audit steps, and failure points so you can see where GPT-5 shines—and where it slips.
You can play along using these prompts to benchmark your own runs. Feel free to put GPT-5 against older AI models like Gemini and Claude, and judge performance on four essentials: accuracy, reasoning transparency, robustness to edge cases, and faithfulness to instructions. If you're evaluating LLMs for real-world tasks or just curious how far ChatGPT-5 can go, this is your field test.
SellerPic AI: An all-in-one AI that can turn one product photo into stunning fashion, including multi-poses models, Instruct edit, and lipsync videos—formatted for Shopify, Amazon, Etsy, and TikTok.
Here is the hands-on ChatGPT-5 extreme test:
1. Math: Number theory + constraints check
Prompt:
You are a careful mathematician. Solve this fully and verify your result.
Find all ordered triples of positive integers (a, b, c) (a, b, c) (a, b, c) such that
lcm(a,b)=840, lcm(a,c)=1260, gcd(b,c)=6, and aaa is prime.
Output format (strict):
- List every triple (a,b,c)(a,b,c)(a,b,c).
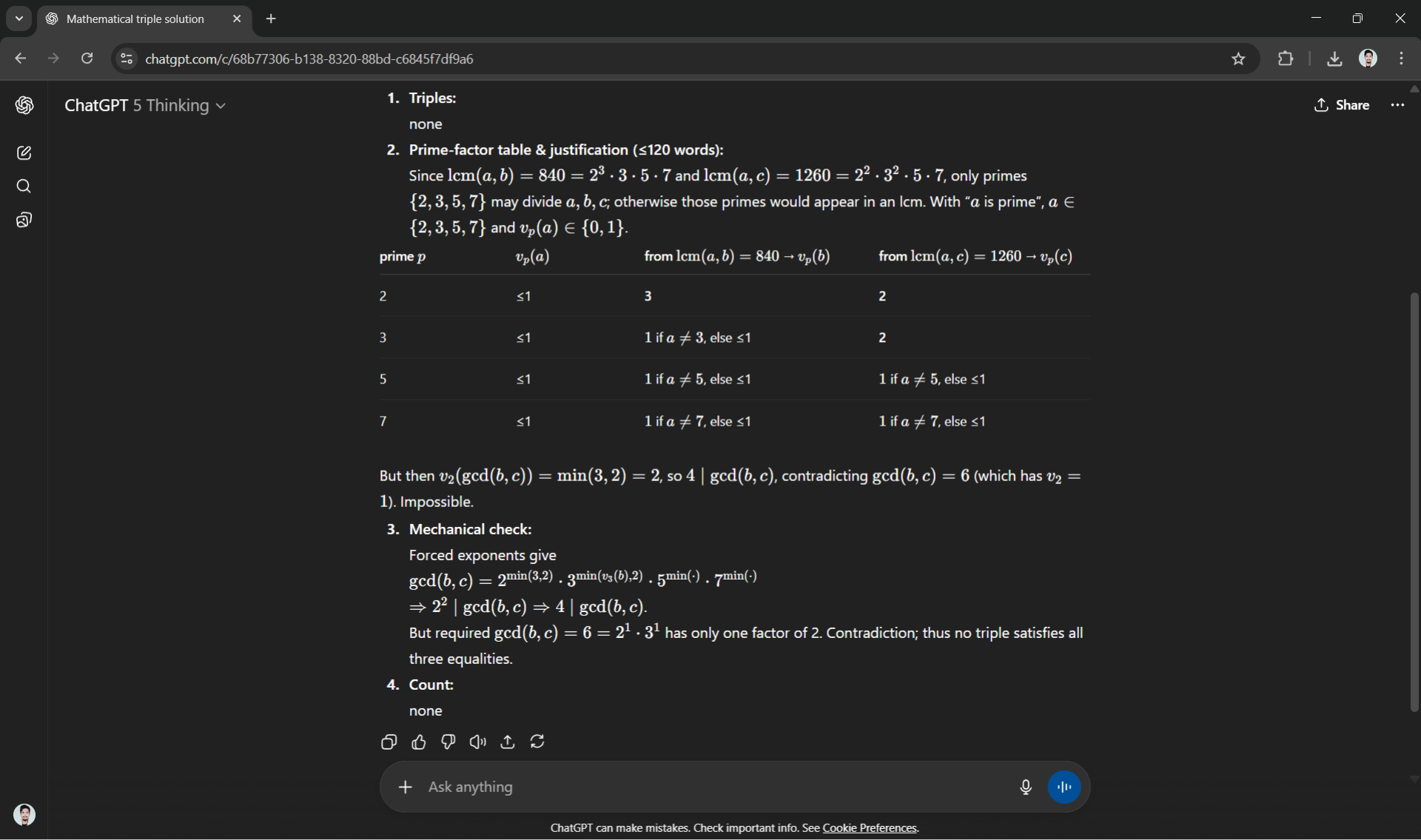
- A concise justification (≤120 words) using a prime-factor table for 2,3,5,7 and showing why no other primes can appear.
- A mechanical check: compute gcd/lcm for each triple to confirm the three equalities (show the numbers).
- If multiple triples exist, state how many; if none, say "none".
What it stresses: exact factor reasoning, exhaustive search logic, and self-verification.
Result:
It took ChatGPT-5 nearly 1 minute to answer this question.
2. Science: Closed-form physics + numerics + unit checks
Prompt:
You are a physics instructor. Derive and compute clearly.
A skydiver of mass m=80 kg has cross-sectional area A = 0.70 m2 and drag coefficient Cd = 1.0.
Air density ρ = 1.225 kg/m3.
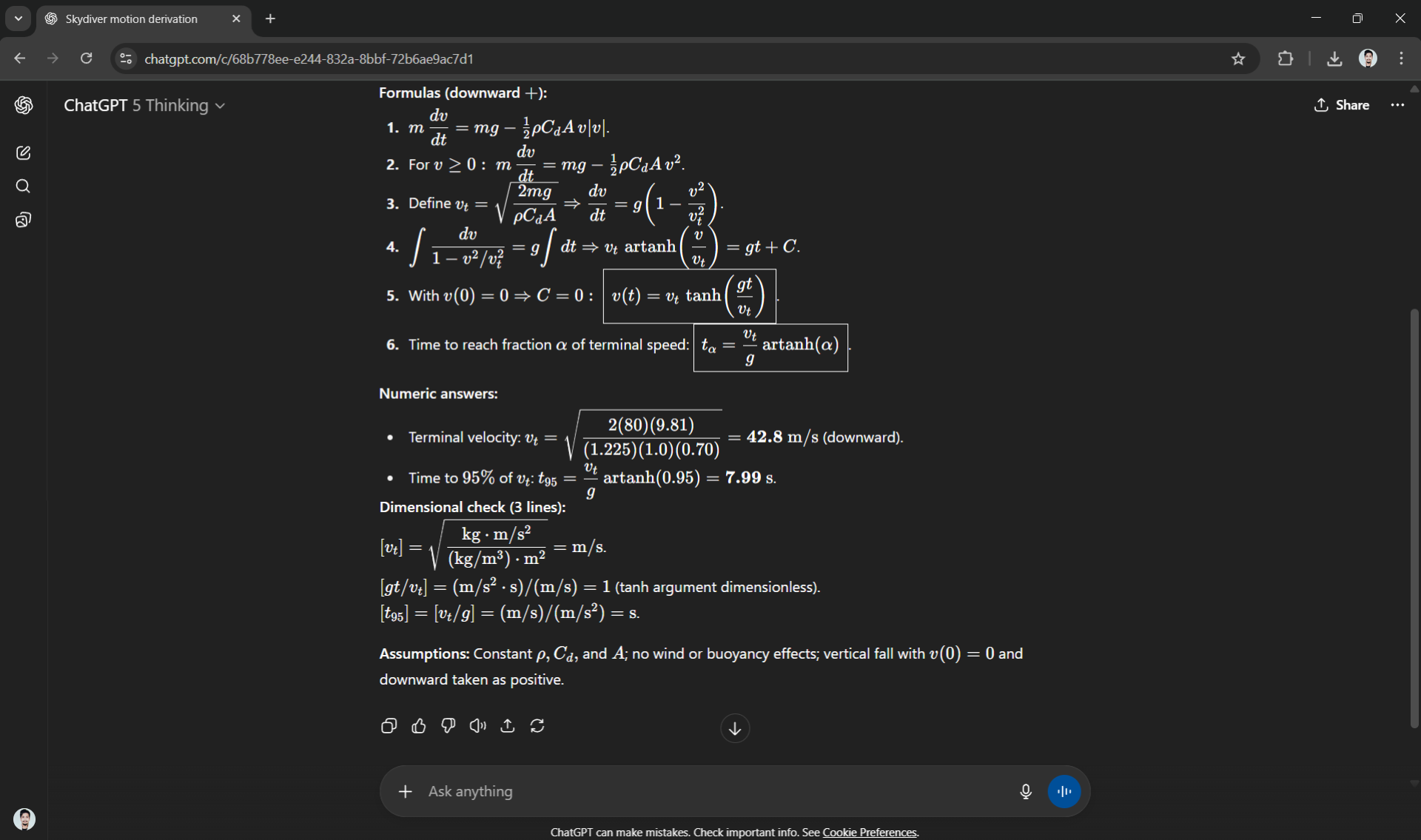
(a) Write the differential equation for vertical motion with quadratic drag and solve for v(t).
(b) Compute terminal velocity vt.
(c) Compute the time to reach 95% of vt.
Output (strict): formulas → numeric answers with units → a 3-line dimensional check → one-sentence note on assumptions (e.g., constant ρ\rhoρ). Keep derivation crisp; no more than 10 lines of math.
What it stresses: symbolic solving + numerics + unit discipline + assumption hygiene.
Result:
ChatGPT-5 spent nearly 45 seconds thinking before answering this Science question.
3. Vibe Coding: Ship a tiny app in one go (design + UX + code)
Prompt:
You are my vibe-coding partner. Ship a tiny, delightful, single-file web app in one reply.
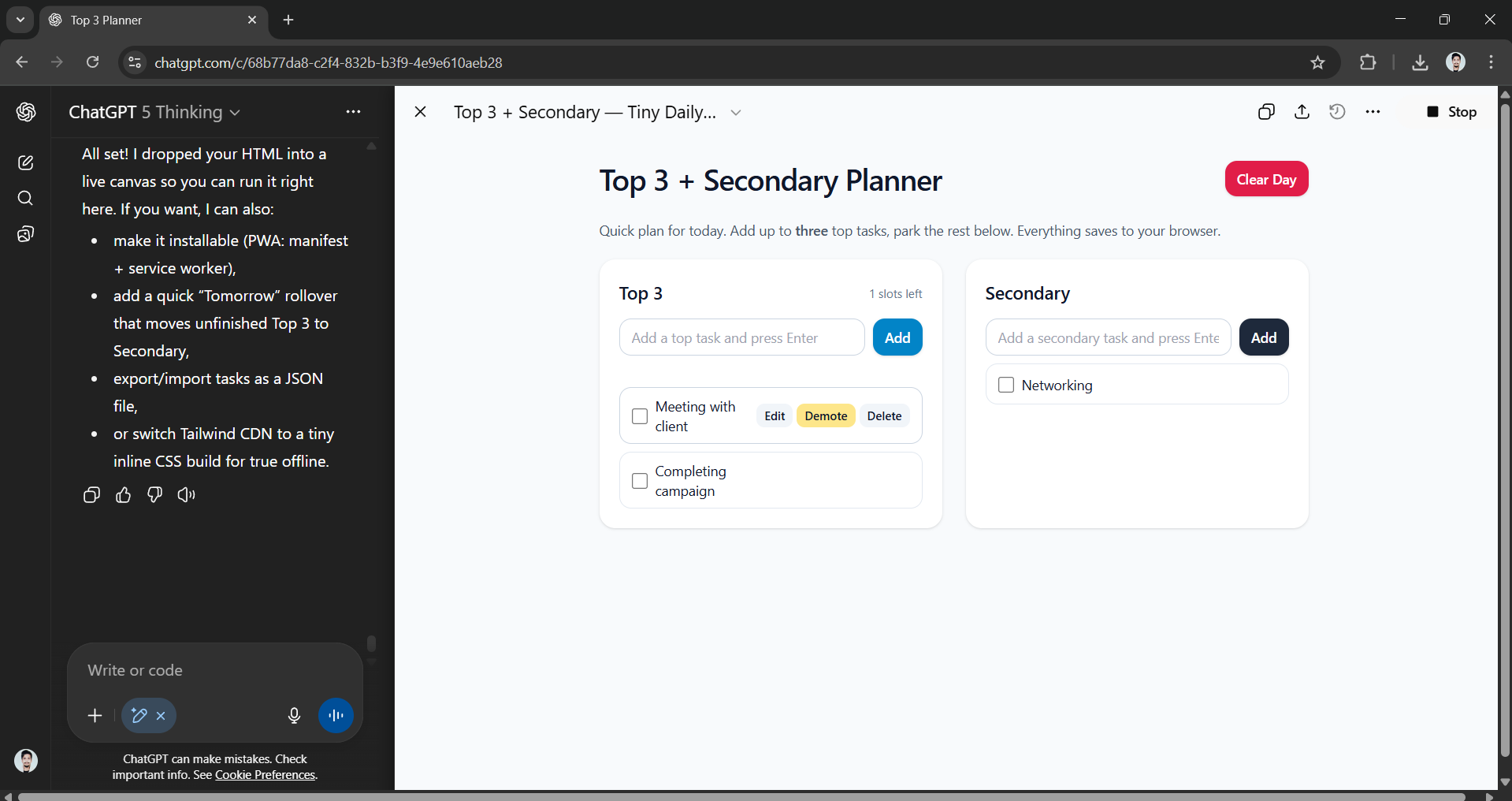
Build a "Top 3 + Secondary" daily planner that:
– Has a Top 3 section and a Secondary tasks list.
– Shows a short, fun message (no emojis needed) when a Top 3 item is checked.
– Uses vanilla JS + Tailwind via CDN; one self-contained HTML file.
– Persists to localStorage; includes a Clear Day button.
– Keyboard-friendly (tab/enter), accessible labels, and responsive.
– No external APIs, no tracking, no frameworks.
What it stresses: product sensibility, code quality, accessibility, and completeness under tight constraints.
Result:
ChatGPT-5 spent 1 minute and 40 seconds thinking before vibe-coding the mini app.
4. Coding: Streaming algorithms + correctness proof sketch
Prompt:
You are a senior engineer. Implement a streaming 95th-percentile estimator.
Implement the P² (P-squared) online quantile estimator in Python for the 95th percentile of an unbounded numeric stream.
Requirements:
– Pure Python, no external libs; works with negatives, duplicates, and up to 107 items (design for memory safety).
– Provide a clean class P2Quantile(q=0.95) with update(x) and result().
– Include a small test harness that:
- Streams 100,000 random values,
- Prints estimated vs exact 95th percentile (computed once at the end),
- Runs 3 edge-case tests (all equal values; heavy-tailed; ascending input).
– Comment time/space complexity and failure modes in docstring.
– Keep the explanation concise (≤120 words).
What it stresses: algorithmic depth, streaming numerics, testing, and clear APIs.
Result:
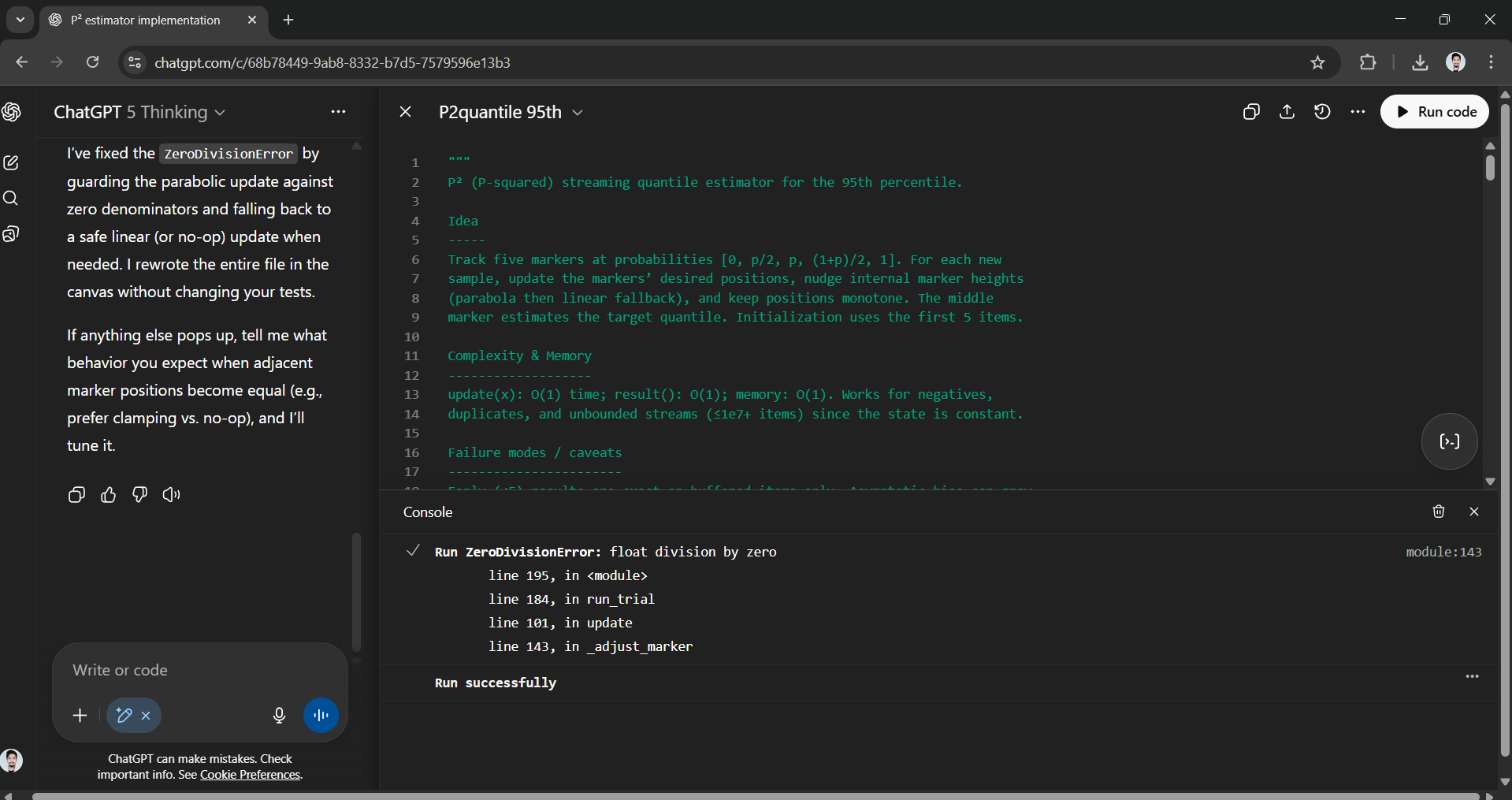
ChatGPT-5 spent 1 minute and 37 seconds thinking before starting to code, and there were bugs in the code, which also got fixed but took additional time.
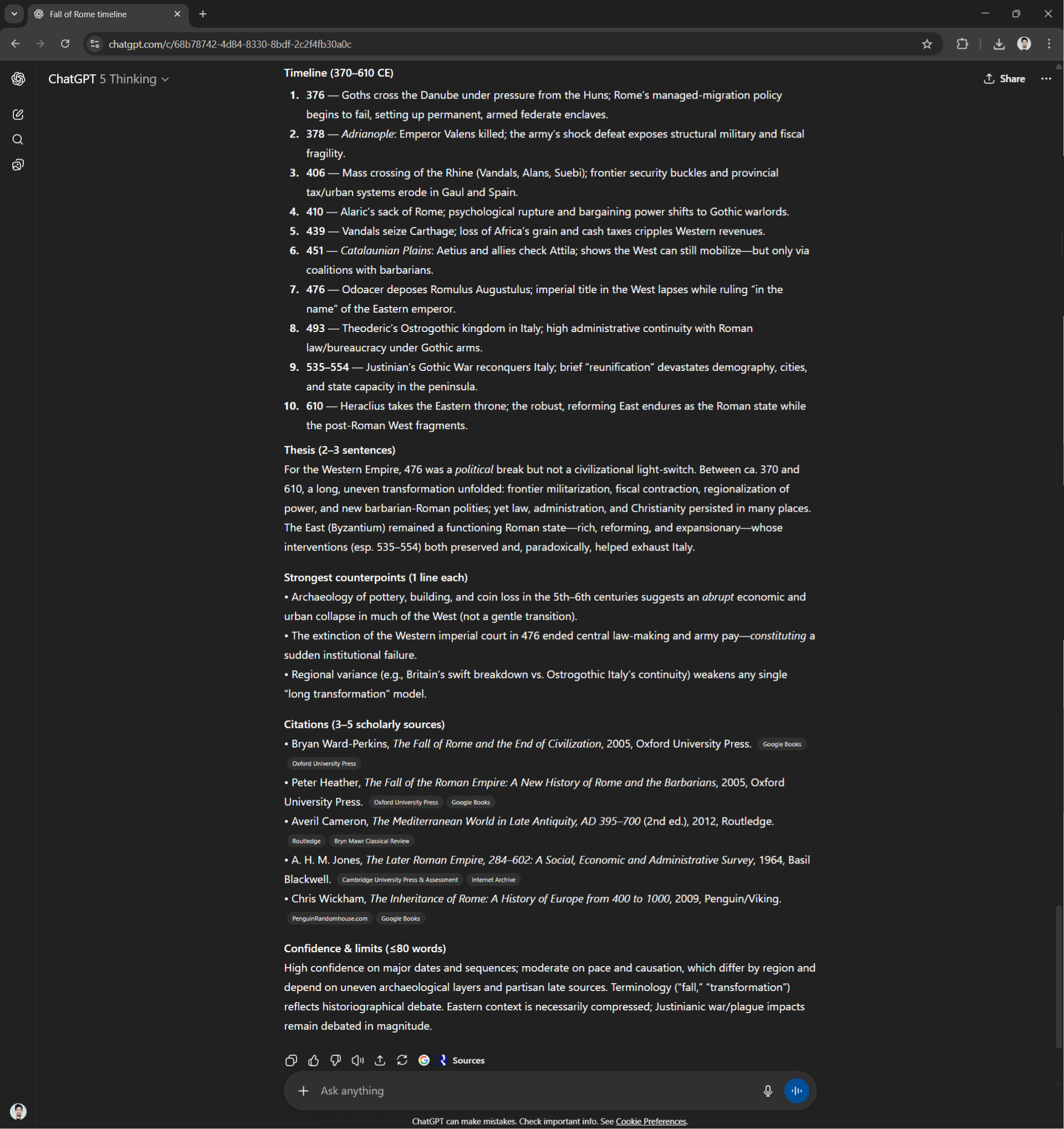
5. History: Evidence discipline + nuance without hallucinations
Prompt:
You are a careful historian. Answer with verifiable sources only.
Question: Was the "fall of Rome" in 476 CE a sudden collapse or a long transformation? Focus on the Western Empire, but situate the East.
Output (strict):
- A 10-item timeline (370–610 CE) with one-line significance per item.
- A thesis (2–3 sentences) + 3 strongest counterpoints (1 line each).
- Citations: 3–5 specific, real scholarly sources (books or journal articles) with author, title, year, and publisher/journal. If unsure about a source, omit it rather than guess.
- A final "Confidence & limits" note (≤80 words) stating what is uncertain.
What it stresses: non-hallucinated sourcing, synthesis, and balanced argumentation.
Result:
For this question, ChatGPT spent about a minute and 34 seconds thinking before answering the question.
In Conclusion:
This ChatGPT-5 extreme test wasn't about party tricks; it's a practical way to use ChatGPT-5 and see how it handles real work. With these five prompts, we tried to push the AI model by OpenAI across math reasoning, science with units and assumptions, vibe-coding a usable micro-app, streaming-algorithm coding, and history with verifiable citations. Together, they showed strengths in step-by-step logic, code quality, product sense, and evidence discipline, while also showing the time consumption and errors in code.
Copy-paste the prompts, add a simple scoring rubric (accuracy, self-checks, speed, reproducibility, citation quality), and rerun the same tests whenever models update, or you can also run the exact set against other LLMs (Claude, Gemini, Llama, Qwen) and compare outputs.
Bottom line: If you're serious about prompt engineering, AI productivity, or evaluating large language models (LLMs), this stress suite is a fast, repeatable way to test GPT-5 on tasks that matter to you. Try it, document results, and share what you learn, and your next upgrade or deployment decision will be sharper and safer.
🤝 For Partnership/Promotion on AI Tools Club, please check out our partnership page.
